例題4-2:ひとつひとつ作業するなんてうんざりだ¶
A: B君、ちょっとそのPCいいかな?…って、作業中か。
B: あ、もうすぐ終わりますんで、ちょっと待っていただけます?
A: OK。やれやれ、どっこいせっと。で、何やってんの?
B: こないだの実験結果のグラフをExcelで描いてるんですが、ちょっと式が間違ってて…
A: 結構たくさん被験者とったんだね。それ、全部手直ししてんの?
B: はい。って、自動でやる方法あるんですか?
A: まあExcelだったらVBAでなんとか出来るだろうし、私だったらpythonの段階で全部処理するね。 グラフも少数ならExcelで描くけど大量に描くならpythonでやっちゃうかな。
B: pythonってグラフも描けるんですか?
A: matplotlibとか使えば描けるよ。まあmatplotlibはいずれmatlabとの絡みで解説しようと思ってたけど、 今そこまで解説するのはちょっときついな。グラフを描く前処理の、複数のテキストファイルに分散した被験者のデータをまとめて処理する方法を教えてあげよう。
B: へ、今からですか?
A: おう。さっき学会の準備が済んだからな。じゃあさっそく適当なサンプルをでっちあげてくるか。ちょっと待ってろよ。
B: ちょっと…。ずいぶんいきなりだなあ。
A: 適当なサンプルになるデータはないかな…っと。これでいいだろ。
120 L 155 231
120 L 275 243
90 L 275 215
120 L 155 227
150 L 155 269
30 R 185 161
60 R 245 193
120 R 155 231
60 L 215 189
150 R 275 275
60 R 215 191
30 L 185 185
60 L 245 191
90 R 215 203
30 R 215 183
30 R 185 183
(以下省略)
B: なんですかこのデータ。
A: 前に実習でMuller-Lyer錯視を扱った時のデータだ。タブ区切りのテキストファイルで、被験者1人につき1ファイルだ。 1つの行に1試行のデータが以下の順番で収められている。
1列目 |
2列目 |
3列目 |
4列目 |
|
内容 |
錯視図形の矢羽の角度。30、60、90、120、150の5種類。 |
錯視図形がスクリーンの左右どちらに表示されていたか。L、Rの2種類 |
比較刺激の最初の長さ。単位はピクセル |
被験者が調節した比較刺激の長さ。単位はピクセル。 |
B: ふむふむ。錯視図形が左右どちらに表示されていたかってどういう意味ですか?
A: ああ、この実験では、画面の左右どちらかに錯視図形、反対側に線分が表示されて、 線分の長さと錯視図形の水平線部分の長さが同じに見えるようにキーボードで線分の長さを調節してもらったのさ。で、この線分の事を比較刺激って呼んでるわけ。

B: なるほど。
A: このMuller-Lyer錯視のプログラムもいずれ例題として紹介したいと思っているけど、 このプログラムは本当にpythonを使い始めの頃に書いたんで、我ながら本当に汚いプログラムなんだよ。いくら恥さらし覚悟で自作プログラムを公開する企画とはいえちょっとアレすぎるからな。 B: Aさんがアレなのはもうとっくにバレてると思うけどなぁ
A: ま、脱線はこのくらいにして錯視図形の矢羽の角度毎に平均を計算してみようか。データファイル名はsbj01.txtとする。
1#!/usr/bin/env python
2# -*- coding: shift-jis -*-
3
4dataFile = open('sbj01.txt','r')
5
6dataNum = [0 for idx in range(5)]
7dataSum = [0 for idx in range(5)]
8
9for line in dataFile:
10 data = line.split('\t')
11
12 if data[0] == '30':
13 idx = 0
14 elif data[0] == '60':
15 idx = 1
16 elif data[0] == '90':
17 idx = 2
18 elif data[0] == '120':
19 idx = 3
20 else:
21 idx = 4
22
23 dataNum[idx] += 1
24 dataSum[idx] += float(data[3])
25
26dataMean = [0 for idx in range(5)]
27
28for idx in range(5):
29 dataMean[idx] = dataSum[idx]/dataNum[idx]
30
31print '%.1f,%.1f,%.1f,%.1f,%.1f\n' % tuple(dataMean)
B: …Aさん、あっという間に書いちゃいましたね。ほんの少しだけ尊敬。
A: これはもう定番の処理だからな。scipyというパッケージなんかには平均を計算する関数があるんでそれを使えばもっと楽に書けるんだけど、 今回は教材も兼ねてあえて自前で計算してみた。このサンプルプログラムのポイントは9行目と11行目。 まず9行目だが、dataFileは7行目で作成したファイルオブジェクト。'r'を指定して開いているから読み込み専用だね。 で、 テキストファイルを開いたファイルオブジェクトに対してfor文を使うと、テキストを1行ずつ読み込んで処理する事ができる んだ。 for x in list:とした時に、xにlistの要素が順番に代入されたのと同じように、9行目の書き方ではlineという変数にテキストファイルの内容が1行ずつ 代入されてループが回る。
B: はあ。なるほど。
A: そしてもうひとつのポイント。11行目のline.split('\t')。splitは例題3-4で紹介したんだが、 大事だからもう一度きちんと言っておこう。文字列が変数lineに収められている時、line.split('\t')は、\tを区切り文字として文字列を分割し、 分割後の文字列をリストとして返す。
B: あの、\tってなんでしたっけ。
A: タブ文字のことだ。キーボード左端のの「Tab」を押して入力する空白文字ね。 プログラム中にタブ文字を入力しても、プログラムを読みやすくするために空白を入れたのか、それとも今回のようにタブ文字を指定したいのかpythonインタプリタには区別できない。 だからタブ文字のような特殊な文字は、特殊な書きかたをして「タブ文字を指定したいんですよ」と教えてやらないといけない。
B: へえ。他にも特殊文字があるんですか?
A: 良く使うのは改行文字の'\n'だな。改行文字ってのは「ここから次の行ですよ」ってのを教えてやるための 特殊文字だ。Mirosoft Wordとか使っていると行の最後に淡い灰色の矢印がついているだろう? あれが改行文字だ。 他にもいろいろあるけど、それはまた機会があれば説明するよ。
B: …あれ、何の話してたんでしたっけ。
A: 11行目のline.split( )の説明だ。今回処理しようとしているデータはタブ文字で区切られているからsplit()の引数に '\t'を指定しているけど、カンマで区切られているなら','と引数に書く。こんな感じだな。
>>> line = '120,L,155,231'
>>> line.split(',')
['120', 'L', '155', '231']
B: ふむふむ。Excelのデータの「区切り位置」みたいな機能ですね。
A: そうだな。今時のプログラム言語は類似の機能を持っているものが多いので 特に何とも思わないかも知れないが、昔のC言語なんかはこういうデータの分割まで自分でいちいちプログラムを書かないと いけなかった。その当時を知っている年寄りとしては本当にありがたい機能だ。
B: へー。そんなもんですか。
A: そんなもんだ。まあ今こうやってやっている事も10年も経てば「昔はこんな面倒な ことをしないといけなかったんだ」とか言ってるかも知れない。さて、サンプル1の解説は以上。
B: へ? もう終わりですか?
A: 後は今までに教えたことと、「平均を計算している」という事がわかれば 自力で読めるはず。がんばりなさい。
B: そんなぁ。
A: まあ、ちょっとだけフォローしておくと、6行目、7行目、27行目は データの個数、和、平均値を格納しておく要素が0で長さが5のリストを作成している。ここには例題3-3で紹介した 内包表記 を使っている。わからなければ例題3-3を復習する事。 あとは25行目。data[3]には被験者の反応が格納されているが、231という値ではなく'231'という文字列が格納されているので、 平均を計算するためには数値に変換してやらないといけない。float( )で浮動小数点数に変換しておけば、後で割り算する時に ちゃんと小数として計算してくれる。最後の32行目は例題4-1の復習だね。
B: むむー。data[0]に矢羽の角度が入っているから、13行目から22行目の if文でデータを格納するリストの要素を指定して、24行目、25行目で実際に格納している。…ですか?
A: 合格。平均の場合はこれでいいんだけど、標準偏差を計算したい場合は もうひと工夫必要になる。まあscipy使った方が楽なんでいずれscipyを紹介するけど、自分で標準偏差を計算するプログラムを 書くのはとても良い練習問題になるから挑戦してみるといい。
B: なんで標準偏差だとひと工夫必要なんですか?
A: 個々のデータから平均を引いた値が必要になるだろ。それを計算するためには 全データのリストと平均値の両方が必要だが、サンプル1では全データのリストを作成していないので、この点を何とかする 必要がある。平均値には別の計算方法もあるから、そっちを使ってもいいんだけど。
B: 別の計算方法…?
A: 統計学の教科書をよーーく読み直してみなさい。ま、それは宿題として、 次はいよいよこのプログラムを複数のテキストファイルに対してまとめて実行できるようにする。
B: あ、そういえばそれが本題でしたね。
A: 実はこの書き換えはあっという間にできる。そら。
行番号なしのソースファイルをダウンロード→ 04-2.py
データファイルの例→ 04-2data.zip
1#!/usr/bin/env python
2# -*- coding: shift-jis -*-
3
4import os
5
6
7allMean = []
8
9for filename in os.listdir(os.getcwdu()):
10 (basename,ext) = os.path.splitext(filename)
11 if ext.upper() != '.TXT':
12 continue
13
14 dataFile = open(filename,'r')
15
16 dataNum = [0 for idx in range(5)]
17 dataSum = [0 for idx in range(5)]
18
19 for line in dataFile:
20
21 data = line.split('\t')
22
23 if data[0] == '30':
24 idx = 0
25 elif data[0] == '60':
26 idx = 1
27 elif data[0] == '90':
28 idx = 2
29 elif data[0] == '120':
30 idx = 3
31 else:
32 idx = 4
33
34 dataNum[idx] += 1
35 dataSum[idx] += float(data[3])
36
37 dataMean = [0 for idx in range(5)]
38
39 for idx in range(5):
40 dataMean[idx] = dataSum[idx]/dataNum[idx]
41
42 dataMean.insert(0,basename)
43 allMean.append(dataMean)
44
45for mdata in allMean:
46 print '%s,%.1f,%.1f,%.1f,%.1f,%.1f' % tuple(mdata)
B: 今度は「あっという間」という割に時間がかかりましたね。
A: うるさい。このサンプルについてはプログラムとサンプルデータをダウンロード 出来るようにしておいたので、試してみてほしい。実行すると以下のように、被験者毎に平均値を計算して画面に出力する。 さらに全被験者の平均を求めたければ最後の45行目から46行目を工夫すればいい。
sbj01,174.4,182.2,205.6,224.0,229.6
sbj02,185.2,184.8,204.0,228.6,246.2
sbj03,165.0,185.2,205.0,225.0,242.0
sbj04,165.0,174.6,195.2,227.6,265.0
sbj05,168.2,191.8,197.8,207.6,221.0
B: あ、あの。サンプルの解説は…
A: おっと、忘れるところだった。まず16行目から40行目はサンプル1のまま。 これらをまとめて一段字下げして、外側にforループを組む。for文でデータファイルをひとつずつ拾っていけば目的達成 なわけだが、これを実現するのがos.listdir()だ。これはosというパッケージの機能で、4行目でimportしている。 os.listdir()は引数に指定されたディレクトリに含まれるすべてのファイルとディレクトリの名前のリストを返す。
B: ああ、ということは9行目は…
A: そう。os.listdir()が作成したファイル&ディレクトリ名一覧から ひとつずつ名前を取り出して、10行目以降の処理をするということだ。これで、データファイルをまとめて処理するという 目的が達成できる。このサンプルのポイントはそれだけだ。
B: なんだか案外簡単なんですね。
A: ポイントはこれだけなんだが、いろいろと気遣いしなきゃならんポイントがある。 まず9行目のlistdir()の引数、os.getcwdu()はプログラムを実行しているディレクトリ(カレントディレクトリ)を得る関数だ。 まあここはパスの表記を知っている人なら'.'と書いときゃ済むんだよと言えばそれまでなんだが、ディレクトリ名を得る方法の サンプルとして載せておいた。ちなみにgetcwdu()はunicodeでディレクトリ名が返ってくるので、日本語のディレクトリ名を 使っている人でも安心だ。
B: ふむふむ。
A: 続いて10行目。ここでは拡張子が'.TXT'以外のファイルは処理しないための 工夫をしている。os.path.splitext( )は引数に与えられた文字列をファイル名と解釈して、ファイル名と拡張子を 分割したタプルを返す関数だ。10行目でextという変数で拡張子を受け取り、11行目から12行目で拡張子が.TXT以外なら 次のファイルへ移る処理をしている。
>>> filename = 'sbj01.txt'
>>> os.path.splitext(filename)
('sbj01', '.txt')
B: 11行目のupper()は文字列を大文字にする関数でしたっけ(例題3-4)。 12行目のcontinueって今までに出てきましたっけ?
A: あー。これは大事な構文なんだが説明していなかったな。 continueは現在のforやwhileのループを中断して次のループに移る。似たような構文にbreakというのがあるが、こちらは ループを終了して次の処理に移る。
B: 次のループ??
A: これは図で示した方がわかりやすいだろうな。
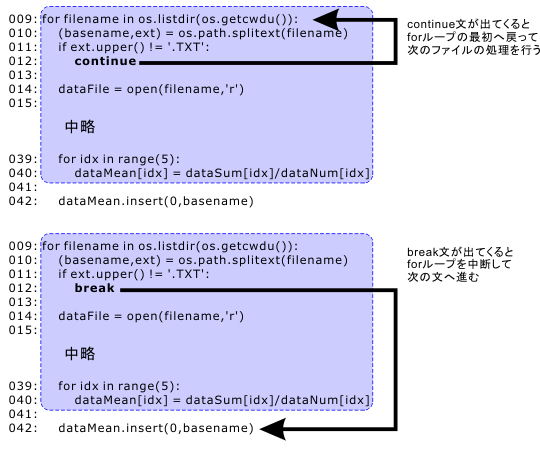
B: continueなら上へ戻る、breakなら下へ抜ける…といった感じでしょうか。
A: continueは残りの処理をすっ飛ばして上へ戻るというのが正しい。 今回のように、「あ、拡張子が.TXTじゃないファイルを見つけちゃった。 このファイルに対しては処理はする必要ないけど、 他にまだ処理が必要なファイルがあるかも知れないな」 という時にcontinueは便利だ。
B: ふむふむ。
A: それに対して、例えば拡張子が'.TXT'じゃないファイルがひとつでも存在するか?ということを 確認したいなら、ひとつでも見つければ 残りのファイルをチェックする必要はない 。こういう場合はbreakを使う。
B: なるほど。
A: 今回は残りのファイルの中に拡張子が'.TXT'のファイルがまだあるかも知れないので、continueを使うのが正解。 breakを使う例も近々出てくるだろう。ちなみに11行目でext == '.TXT'ではなくてext.upper() == '.TXT'になっている理由はわかるか?
B: えーと、ファイル名が'○○.txt'みたいに小文字になってるかも知れない、から?
A: その通り。11行目のif文にひっかからなければ、少なくとも拡張子は'.TXT'であることは 間違いないので、open( )関数でファイルを開く。テキストファイルじゃないファイルに'.TXT'ってつけてたらここで予想外のハプニングが 起こるかも知れないけど、そういう行儀の悪い事はしていないという前提で。
B: 逆にテキストファイルなのに'.TXT'以外の拡張子をつけるパターンならぼくはよくやりますが。
A: そういうのも今回は配慮していないので自分で気をつけるかプログラムを工夫すること。 ちなみにファイル名はfilenameという変数に入っているので、14行目のopen( )の引数にもこれを使う。 あと、説明が必要なのは…っと。42行目。最後に平均値を出力する時に、どの行がどの被験者の平均値かわからなくなるとアレなので、 insert()でリストの先頭にファイル名を挿入している。ここでは'.TXT'がついていると鬱陶しいので、10行目のos.path.splitext()の 戻り値を流用している。
B: ファイル名がテキトーだと役に立ちませんね。
A: こういう利用も見越してファイル名をつけておかないといけないぞ。 テキトーにつけて後でわからなくなったら目もあてられん。
B: はーい。
A: あとは、dataMeanは次の被験者のデータ処理に入ると上書きされてしまうので、 どこかに保存しておかないといけない。そのためのリストallMeanを7行目で初期化している。被験者は何人いるかわからないので ここでは空リストとして作成しておいて、43行目でどんどんappendしていくという形で保存している。こうすれば、被験者が10人だろうが100人だろうが安心だ。
B: 100人分もデータを詰め込んで大丈夫なんですか?
A: ひとりあたりのデータ量がこの程度なら、今どきのコンピュータは100人分なんてびくともしない。
B: へー。そりゃ頼もしい。
A: さて、これで「ファイルをまとめて処理する」方法の基本を一通り解説できたかな。 複数のディレクトリにデータが分散している場合とか、もっと複雑な統計処理とか、グラフの描画とか、上を目指すときりがないので 今回はこのあたりで終わっておくのがいいだろう。ここで説明しただけでも、かなり作業は楽になるはず。被験者が5人やそこらなら Excelの方があれこれ試行錯誤しながら作業できるからいいかもしれないが、被験者数が10人、20人と増えてくると、プログラムで 処理するメリットがぐんぐん大きくなる。まあ、こういうデータ処理プログラムも慣れの要素が大きいので、Excelで簡単に処理 出来るデータでもまず一度自分で処理プログラムを書いてみてほしい。今回はこれにて終了!
B: ありがとうございましたー。