anova君用入出力インターフェース"repAnova"¶
2013/12/05 (2013/12/10 修正)
現在のrepAnovaはANOVA君4.4.0との組み合わせでは動作しません。対応バージョンを開発する予定ですが、しばらく先になる予定です。ANOVA君4.4.0においてLong形式のデータや要因名、水準名の指定がサポートされましたので、今後はrepAnovaなしでもこれらの機能が利用できます。詳しくは ANOVA君/より高度な入力方式 をご覧ください。
Rで繰り返しのある分散分析を下位検定まで含めて実行してくれる「anova君」というありがたいツールがあります。 とってもありがたいのですが、要因名や水準名がa1,a2,...といった記号で出てくるで学部生の卒業研究などで他人が処理した結果を見る時に"MULTIPLE COMPARISON for FACTOR B at a1"とかいう出力を見てBやa1が何を意味しているのかわからず困ってしまいます。 そこで、anova君を構成する関数をごっそりお借りして入出力を書き直した関数repAnova()を作ってみました。
anova君の関数をお借りして分散分析を行います。 別途anova君を入手する必要があります 。
HTML形式で結果を出力します。入力したデータで使われていた要因名や水準名が表示されます。
動作確認と言っても手持ちのデータをいくつか放りこんでみただけなので、多分おかしいところがあります。この関数の使用によって生じるいかなる結果に関しても責任を負いかねます。
Matlab/OctaveからrepAnovaを呼び出す RrepAnova を用意しています。
repAnova.r (最終更新日:2013/10/31)
更新履歴¶
2013/10/31
CSSのサポートを拡張して数値を右寄せで表示できるようにしました(Internet Explorer10, FireFox24.0で確認)。詳しくは「CSS対応」をご覧ください。
2013/10/30
anovakun 4.3.3で動作テスト。
以下のオプションを追加サポート。
nopost
eta
geta
eps
peps
geps
omega
omegana
gomega
gomegana
(注)copyはサポートされていません。
2011/12/3
anovakun形式のデータフレームをrepAnova形式に変換する補助関数anovakun2repAnovaを追加。
2011/12/2
2要因計画で交互作用があった時に余分な表が出力されていた問題を修正。
2010/3/12
techオプションの削除。
修正Bonferroniの表で有意差を示す記号(*)が欠けていた問題を修正。
Sphericity Indicesの表レイアウトが崩れていた問題を修正。
単純主効果の出力でpartepsiがNULLの時にエラーが起こる問題を修正。
外部CSSファイルを指定できるようオプションcssを追加。
表にの列にlabel、value、signのクラスを設定。CSSでクラス別に書式設定可能に。 もともとテキストの右寄せ、左寄せなどを列ごとに設定できるようにするつもりで追加しましたが、後からcolでtext-alignを適用できないと知ってがっかり。何かに使えるかもしれないので一応残してありますが、あまり使い道はないかもしれません。
0.05未満のp(p.adj)値にspan.sigmarkというクラスを設定。CSSでこれらの値の書式設定可能に。
2010/1/29
公開。
使い方¶
ひとつの列がひとつの要因に対応するようにデータを並べ、タブ区切りやCSV形式など、Rで読み込める形式で保存してください。 SPSSやstatistica、anovakunとは異なり、被験者も要因としてラベルを付けてひとつの列に並べます(Rのaov()やMatlab/Statistics Toolboxのanovan()と同じ形式です)。 例として、被験者間要因が「利用経験」、被験者内要因が「アイテム数」と「ISI」で正答率を比較するとします。 anova君の形式で言うと"AsBC"デザインでA=利用経験、B=アイテム数、C=ISIです。 この場合、以下のようにデータを並べます。この例では左の列から優先的にソートしていますが、repAnovaが内部でソートしますのでバラバラに並んでいても構いません。また、列名で要因等を指定しますので、列の順番もこの通りでなくて構いません。
被験者 |
利用経験 |
アイテム数 |
ISI |
正答率 |
s1 |
多い |
3個 |
400ms |
0.86 |
s1 |
多い |
3個 |
800ms |
0.84 |
s1 |
多い |
6個 |
400ms |
0.78 |
s1 |
多い |
6個 |
800ms |
0.83 |
s1 |
多い |
9個 |
400ms |
0.69 |
s1 |
多い |
9個 |
800ms |
0.71 |
s2 |
少ない |
3個 |
400ms |
0.75 |
s2 |
少ない |
3個 |
800ms |
0.75 |
s2 |
少ない |
6個 |
400ms |
0.63 |
s2 |
少ない |
6個 |
800ms |
0.73 |
s2 |
少ない |
9個 |
400ms |
0.52 |
s2 |
少ない |
9個 |
800ms |
0.69 |
s3 |
多い |
3個 |
400ms |
0.85 |
s4 |
多い |
3個 |
800ms |
0.87 |
(以下略) |
Rでanovakun()、repAnova()とこのデータを読み込み、以下のようにrepAnovaを実行します。anovakun.rやrepAnova.rをカレントディレクトリ以外に置いている場合はパスを書いてください。ヘッダ無しでデータを作成して"V1"などの列名で要因等を指定することも出来ますが、その場合は当然出力でも要因名が"V1"などと表示されてしまいます。
> source("anovakun.r")
> source("repAnova.r")
> data <- read.table("data.txt",header=T)
> repAnova(data,"被験者","利用経験",c("アイテム数","ISI"),"正答率")
特に問題が生じなければカレントディレクトリにrepAnova_output.htmlというファイルが作成され、自動的にブラウザで表示されます。 要因や水準の名前が書きかえられている以外はanova君の出力と(ほぼ)同じになっているはずです。
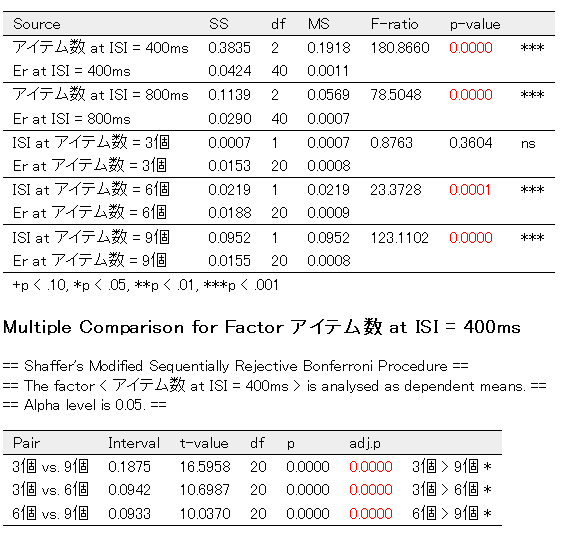
repAnova()の使い方の詳細は以下の通りです。
> repAnova(dataframe, s, betvar, withvar, data, ...)
dataframe |
データが格納されたデータフレームを指定します。省略できません。 |
s |
被験者を表す記号が入力された列名を指定します。被験者内要因がひとつもない場合はNULLを指定して省略することが出来ます。 被験者内要因がある場合は省略できません。 |
betvar |
被験者間要因変数が入力された列名を指定します。被験者間要因がひとつもない場合はNULLを指定します。複数の要因がある場合は 列名をベクトルで指定します。 |
withvar |
被験者内要因変数が入力された列名を指定します。被験者内要因がひとつもない場合はNULLを指定します。複数の要因がある場合は 列名をベクトルで指定します。 |
data |
比較する数値が入力された列名を指定します。省略できません。 |
... |
追加のオプションを指定します。基本的にanovakun4.0のオプションと同じですが、 data.frame と tech は使用できません。 以下のオプションがrepAnovaで新たに追加されています。 |
その他 |
anovakun4.1.0で追加された欠損値の除外は対応していません。結果の出力において水準はRのvector()とorder()の規則に従って数値化され並べ替えられるため、"12月"が"7月"の前に来るなど見栄えの良くない出力になってしまうことがあります。この問題に対応する予定はありません。 |
おまけ:anovakun形式のデータフレームをrepAnova形式に変換するanovakun2repAnova¶
repAnovaのデバッグをする時にデータフレームを手作業で用意するのが面倒くさいので作りました。
> anovakun2repAnova(data, between, within, withinlevels)
data |
anovakun形式のデータが格納されたデータフレームを指定します。 |
between |
被験者間要因が格納された列につけたいラベルを並べたベクトルまたはリストを指定します。被験者間要因が一つしかない場合は文字列でも構いません。被験者間要因がない場合はNULLを指定します。 |
within |
被験者内要因が格納された列につけたいラベルを並べたベクトルまたはリストを指定します。被験者内要因が一つしかない場合は文字列でも構いません。 被験者内要因がない場合は変換作業が必要ありませんので何もせずに終了します。 |
withinlevels |
被験者内要因の各水準に付けるラベルを並べたリストを指定します。被験者内要因が1つしかない場合はベクトルでも構いません。 |
使用例1:被験者間要因:性別、被験者内要因:刺激(怒、喜、悲の3水準)
> anovakun2repAnova(data,'性別','刺激',list('怒','喜','悲'))
> anovakun2repAnova(data,'性別','刺激',c('怒','喜','悲')) #被験者内要因がひとつしかないのでベクトルでも可
使用例2:被験者間要因:なし、被験者内要因:アイテム数(4,8,12の3水準)×色(カラー、モノクロの2水準)
> anovakun2repAnova(data,NULL,list('アイテム数','色'),list(list('4','8','12'),list('カラー','モノクロ')))
CSS対応¶
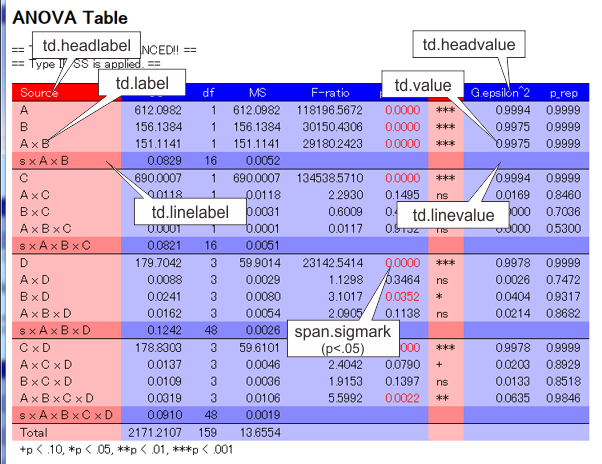
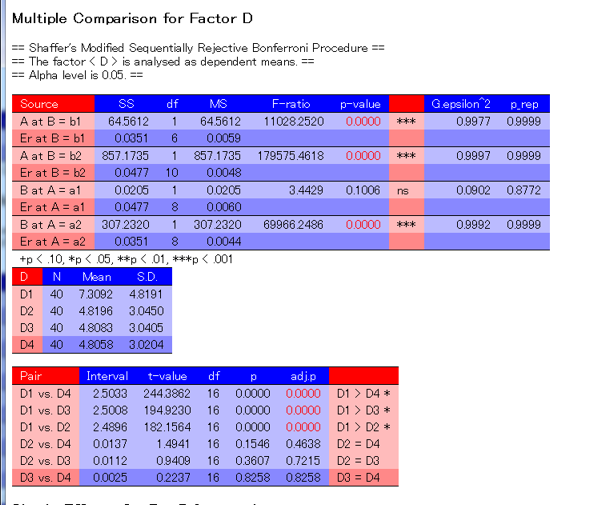
repAnovaを呼び出す時に、cssオプションにCSS(Cascading Style Sheets)ファイル名を指定すると、表のレイアウトを調節することが出来ます。 repAnovaの出力で使用されているクラスは以下の通りです。
td.headlabel |
要因名や水準名などのラベルが表示される列の見出し行に対する書式設定です。 |
td.label |
要因名や水準名などのラベルが表示される列の書式設定です。ただし、最終行などのように下線が引かれる行はtd.linelabelで指定します。 |
td.linelabel |
要因名や水準名などのラベルが表示される列のうち、最終行などのように下線が引かれる行に対する書式設定です。 |
td.headvalue |
F値や効果量などの数値が表示される列の見出し行に対する書式設定です。 |
td.value |
F値や効果量などの数値が表示される列の書式設定です。ただし、最終行などのように下線が引かれる行はtd.linevalueで指定します。 |
td.linevalue |
F値や効果量などの数値が表示される列のうち、最終行などのように下線が引かれる行に対する書式設定です。 |
span.sigmark |
0.05より小さいp値を示す数値に対する書式設定です。 |
col.label |
要因名や水準名などのラベルが表示される列に対する書式指定です。td.label、td.headlabelおよびtd.linelabelを使う方がブラウザに依存しない出力が得られると思われますが、互換性のために残してあります。 |
col.value |
数値が表示される列に対する書式指定です。td.value、td.headvalueおよびtd.linevalueを使う方がブラウザに依存しない出力が得られると思われますが、互換性のために残してあります。 |
col.sign |
有意差を示す記号(ns や *など)が表示される列に対する書式指定です。td.label、td.headlabelおよびtd.linelabelを使う方がブラウザに依存しない出力が得られると思われますが、互換性のために残してあります。 |
使用例を示します。以下のCSSファイルをtest.cssという名前で保存し、revAnovaを実行するカレントディレクトリに置きます。なお、このtest.cssは上記のクラス名と出力の対応がわかりやすいようにわざと色を付けてありますので、あまり実用的ではありません。
table{
border-collapse: collapse;
}
td{
padding:2px 10px;
white-space: nowrap;
}
col.label{
background-color:FFFFFF;
}
col.sign{
background-color:FFFFFF;
}
col.value{
background-color:FFFFFF;
}
span.sigmark{
color:#FF0000;
}
td.headlabel{
border-style: solid;
border-color: black;
border-width: 1px 0px 1px 0px;
background-color:#FF0000;
color:#FFFFFF;
}
td.headvalue{
text-align:center;
border-style: solid;
border-color: black;
border-width: 1px 0px 1px 0px;
background-color:#0000FF;
color:#FFFFFF;
}
td.label{
text-align:left;
background-color:#FFBBBB;
}
td.linelabel{
border-style: solid;
border-color: black;
border-width: 0px 0px 1px 0px;
background-color:#FF8888;
}
td.value{
text-align:right;
background-color:#BBBBFF;
}
td.linevalue {
text-align:right;
border-style: solid;
border-color: black;
border-width: 0px 0px 1px 0px;
background-color:#8888FF;
}
CSSオプションを指定してrepAnovaを呼び出します。
repAnova(data2,"sbj",c("A","B"),c("C","D"),"data",geps=T,prep=T,css="test.css")
以下のような出力が得られます。色やフォント、余白などを調節するには一般的なCSSの解説をご覧ください。
サクラエディタ用Rキーワードファイル¶
サクラエディタでの作業用にMatlab用同様にテキトーに作りました。単にFAQに掲載されている一覧をコピペしただけです。
Portable RでRMeCabを強引に使う¶
MeCabをRから利用するRMeCabはとても便利なのですが、大学の計算機室のPCなど、自分でアプリケーションをインストールできないWindows PCでRMeCabを使おうとするとMeCabの位置でハマります。というのもRMeCabはMeCabがC:\Program Files\MeCabかC:\Program Files (x86)\MeCabにインストールされていることが前提となっているからです(2014年10月現在)。通常、C:\Program FilesやC:\Program Files (x86)には管理者の権限がないとアプリケーションをインストールすることが出来ません。
そういう時はUSBメモリに展開したMeCabを参照できるようにRMeCabにパッチを当てるのが 正しい姿 だと思うのですが、Rの開発環境を用意するのが面倒くさくてあっさり挫折しました。で、ソースをぼんやり眺めていると単にレジストリを参照しているだけのようだったので、レジストリを毎回書き換えるという強引な方法を試してみたらそれっぽく動いたので紹介しておきます。
USBメモリのルートに以下のフォルダが置かれているとします。
R-Portable … Portable Rの本体。直下にR-Portable.exeがある。
MeCab … RMeCabのバージョンに対応するMeCab。
USBメモリのルート(すなわちR-PortableやMeCabディレクトリがある場所)に以下のバッチファイルを置きます。名前は何でもいいですがmecabreg.batとします。
echo off
REM --------------------------------
REM Check registory
reg query HKCU\Software\MeCab
if %ERRORLEVEL%==0 goto FOUND
REM --------------------------------
REM MeCab is not found in registory
REM add registory entry
reg add HKCU\Software\MeCab /v mecabrc /t REG_SZ -d "%~dp0MeCab\etc\mecabrc"
REM start R-Portable
cd %~dp0work
%~dp0R-Portable\R-Portable.exe
REM remove registory entry
reg delete HKCU\Software\MeCab /f
goto END
REM --------------------------------
REM MeCab is found in registory
:FOUND
REM start R-Portable
cd %d~work
%~dp0R-Portable\R-Portable.exe
REM --------------------------------
REM end
:END
echo on
mecabreg.batを起動するとPortable Rが起動します。 install.packages()を使ってRMeCabをインストールします。以後、USBメモリ上のmecabreg.batからPortable Rを起動すればRMeCabが使えるはずです。
毎回レジストリにエントリを追加したり消したりするのでなんだか イヤな感じ ですが、とりあえず筆者の勤務校の計算機室PCでは問題なく動作しているようです。
Portable RでRStanを使う¶
StanをRから利用するRStanはとても便利なのですが、大学の計算機室のPCなど、自分でアプリケーションをインストールできないWindows PCでRStanを使おうとすると困ります。ってRMeCabと同じパターンですな。
というわけでPortable RからRStanを使えるようにしてみます。こちらはRMeCabより話は簡単で、RToolsをどこかに用意しておいて、Rguiの起動前に環境変数を設定してやるだけです。
Portable Rを展開する。ここでは https://sourceforge.net/projects/rportable/Potable からR 3.3.3を入手してE:\R-Portableに展開したとする。
https://cran.r-project.org/bin/windows/Rtools/ から使用するRのバージョンに対応したRToolsを入手する。この例ではRtools34.exeを使う。
RToolsを適当な場所にインストールして、RToolsディレクトリ(標準ではC:\RTools)をまるごとPortable Rのディレクトリ(この例ではE:\R-Portable)にコピーする。コピー後はRToolsをアンインストールしてしまってよい。
以下のバッチファイルをPortable Rのディレクトリ(この例ではE:\R-Portable)に作成する。名前はなんでもよいがここではR-Porable.batとしておく。
echo off
REM --------------------------------
REM Set PATH
SET PATH=%~dp0Rtools\bin;%~dp0Rtools\mingw_32\bin;%PATH%
REM --------------------------------
REM Set BINPREF
SET CXXPATH=%~dp0Rtools\mingw_32\bin\
SET BINPREF=%CXXPATH:\=/%
REM --------------------------------
REM Start R-Portable
R-Portable.exe
echo on
R-Portable.batを実行する。Portable Rが起動する。
R上でrstanをインストールする。
以後、R-Porable.batからPortable Rを起動すればRStanが使えるはずです。
ポイントはバッチファイルで環境変数PATHにRToolsの実行ファイルとCコンパイラへのパスを追加していることと、環境変数BINPREFにCコンパイラへのパスを設定していることです。BINPREFで\を/に置換していますが必要ないかも知れません。RToolsのバージョンによってCコンパイラの位置が異なりますので、RToolsディレクトリの中を覗いてみてもしmingw_32ディレクトリが無ければg++.exeを含んでいるディレクトリに変更してください(バッチファイルの4行目と8行目のmingw_32を書き換え)。
なお、現在配布されているPortable R 3.3.3は32bit版なので、mingw_64ではなくmingw_32を使っています。RStanのドキュメント(https://github.com/stan-dev/rstan/wiki/Installing-RStan-on-Windows )ではMakevarsを設定することを勧めていますが、ここでは設定していません。