10. 無作為化しよう―視覚探索¶
10.1. この章の実験の概要¶
いよいよ本書も最後の章です。前章では、Builderに対する不満として「条件分岐が出来ない」という点を挙げて、Codeコンポーネントで解決を試みました。この章では、「十数個の視覚刺激を描画するのが面倒」、「すべてのパラメータを明示的に条件ファイルで与えるのが面倒」という問題を取り上げたいと思います。
この章の例題として挙げる実験は、視覚探索課題です。 図10.1 に視覚探索課題の例を示します。 図10.1 の(1)では、スクリーン上に切れ目が入っている円(以下Cと表記)が複数個提示されていますが、50%の確率で一つだけ切れ目がない円(以下Oと表記)が含まれています。実験参加者は、出来るだけ速く正確に、Oが含まれているか居ないかを判断しなければいけません。容易に予想出来る事ですが、Oの有無を判断するまでに要する平均時間はスクリーン上に提示されている図形(以下アイテムと表記)の個数にほぼ比例して増加します。ところが、 図10.1 の(2)のように、OとCを入れ替えて、複数個のOの中からCの有無を判断する課題に切り替えると、アイテム数が増えても(1)ほど反応時間が増加しません。この現象を視覚探索の非対称性と呼び、 図10.1 下のようにアイテム数と平均探索時間の関係をプロットしたグラフを探索関数と呼びます。参加者が探し出すべきアイテムをターゲットと呼び、それ以外のアイテムをディストラクタと呼びます。(1)の課題ではOがターゲットでCがディストラクタ、(2)の課題ではCがターゲットでOがディストラクタです。この章では、アイテム数を5個、10個、15個と変化させながら(1)の課題と(2)の課題を行う実験を作成します。
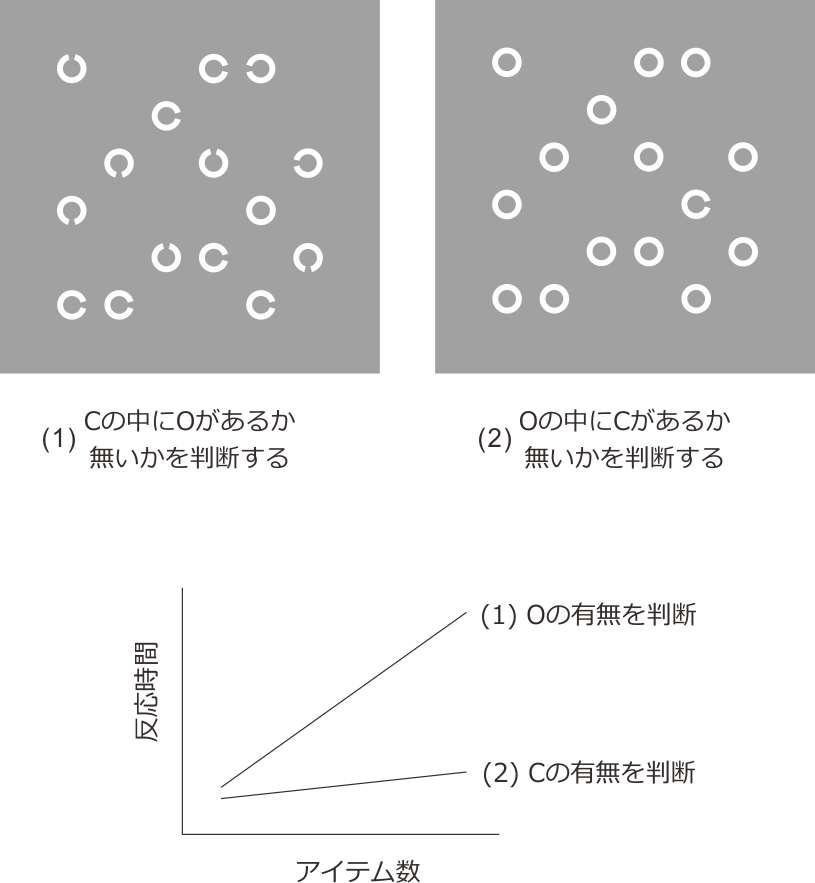
図10.1 視覚探索の非対称性。スクリーン上に提示されているアイテム数が多いほど判断に時間がかかりますが、CのなかからOを探すより、Oの中からCを探す方がアイテム数増加に伴って反応時間が急激に増加します。
図10.2 に具体的な手続きを示します。実験を実行すると、準備が出来たらカーソルキーの左右を押すように促す教示が提示されます。このスクリーンを1.とします。実験参加者が自分でキーを押すことによって実験が始まります。各試行の最初には、スクリーン中央に固視点として 文字の高さ $ が24pixの「+」の文字が提示されます。このスクリーンを2.とします。実験参加者は固視点を注視しながら刺激の提示を待ちます。待ち時間は試行毎に1.0秒、1.5秒、2.0秒のいずれかから無作為に選びます。待ち時間が終了したら、スクリーン上に刺激が提示されます。刺激はアイテム数が3種類(5個、10個、15個)×アイテムの種類が4種類(すべてO、すべてC、Oの中にひとつだけC、Cの中にひとつだけO)=12種類のいずれかです。実験参加者は、刺激の中に「ひとつだけ周囲と異なるアイテムが存在するか否か」を判断します。ひとつだけ周囲と異なるアイテムが存在する場合はカーソルキーの右、すべて同じアイテムの場合はカーソルキーの左を出来るだけ速く、正確に押します。反応に制限時間は設けず、参加者が反応するまで刺激を提示します。参加者が反応したら自動的に次の試行が開始されスクリーン2.(固視点が提示される画面)へ戻りますが、80試行毎に休憩のためにスクリーン1.へ戻って参加者のスペースキー押しを待ちます。12種類の条件に対して20試行ずつ、合計240試行を無作為な順序に実施したら実験は終了します。総試行数が240試行で80試行毎にスクリーン1.が挿入されるのですから、スクリーン1.は実験開始直後、80試行終了時、160試行終了時の3回提示されます。
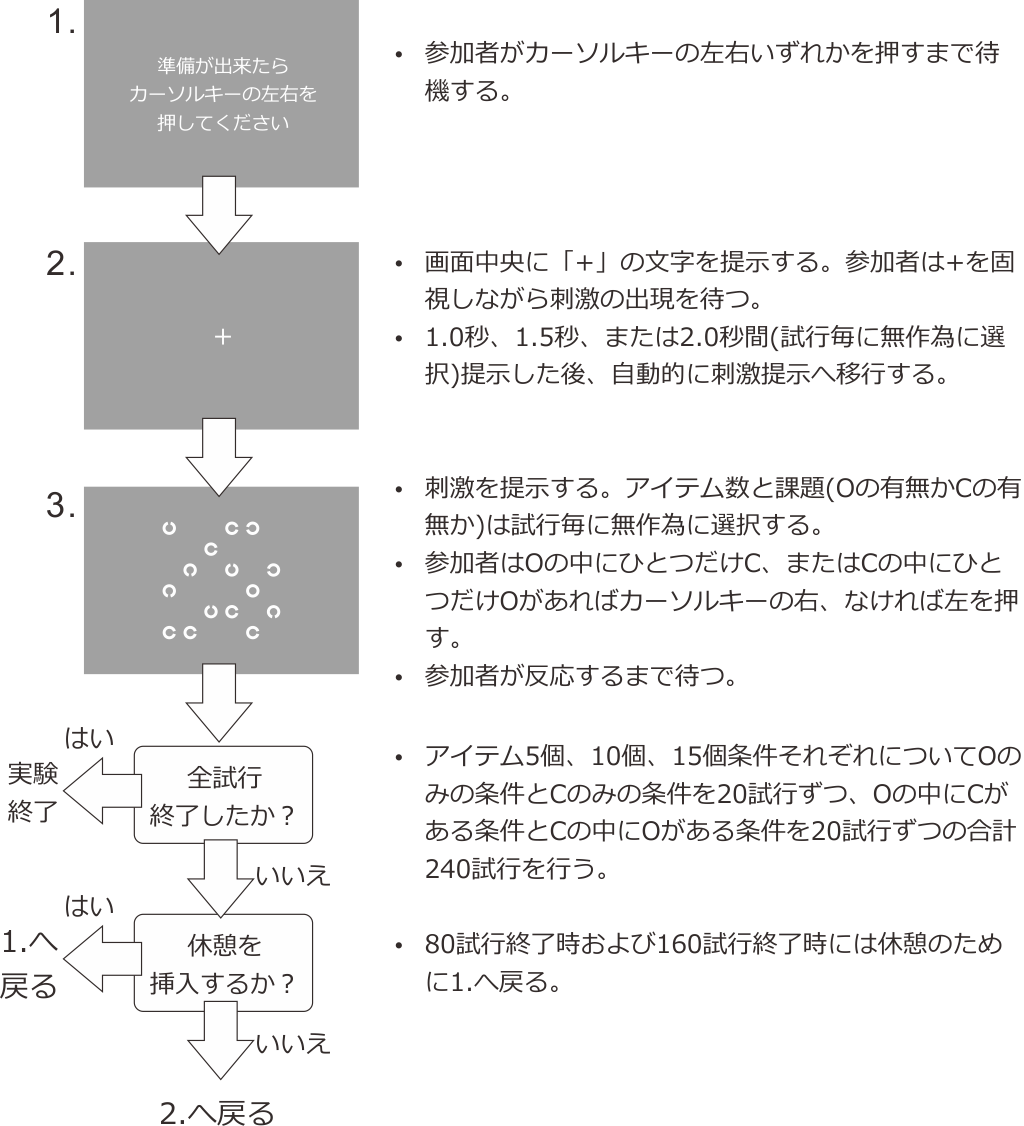
図10.2 実験の手続き。
刺激の詳細を 図10.3 に示します。アイテムの位置はスクリーン中央に設定された仮想的な6×6の格子上から無作為に選ばれます。格子の各マスの幅および高さは100pixです。スクリーン中央の座標が[0, 0]で、グリッドの全幅は500pixですから、グリッドの一番右上の座標は[250,250]、一番左下の座標は[-250, -250]です。一番上の段の座標を左から右に向かって順番に書くと、[-250, 250]、[-150, 250]、[-50, 250]、[50, 250]、[150, 250]、[250, 250]です。
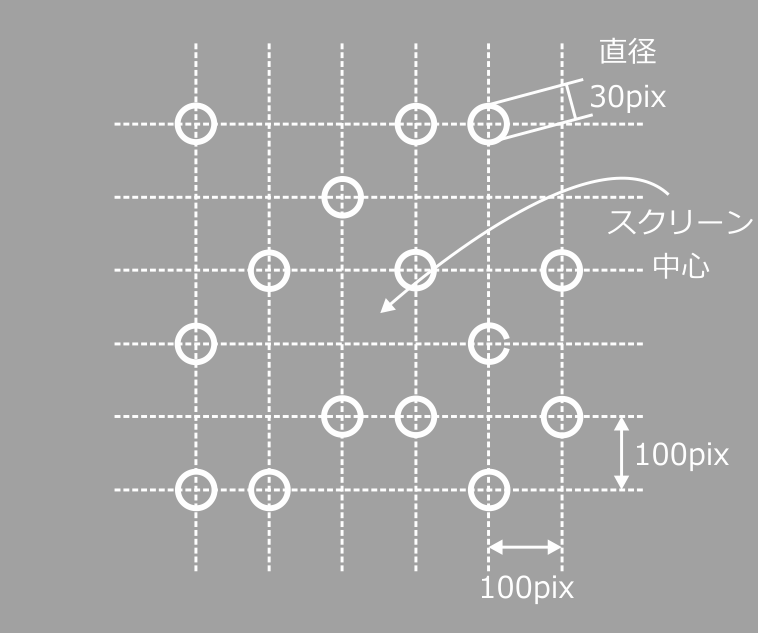
図10.3 刺激の配置。アイテムの位置は仮想的な6×6のグリッド上から試行毎に無作為に選択されます。
アイテムの直径はO、Cともに30pixとし、Cの場合は円の一部に幅10pixの切れ目を入れます。切れ目の位置は、アイテムの中心から見て右を0度として、時計回りに0度、90度、180度、270度の4種類の中からアイテム毎に無作為に選択します。
以上が実験の概要です。Builderが苦手とするポイント、出来る事ならBuilderで作りたくないなあと思ってしまうポイントがいくつか含まれています。これらのポイントはお互いに関連しあっているのですが、敢えて箇条書きにすると以下の4点が挙げられます。
- 独立に位置や形状が変化するアイテムが最大15個もスクリーン上に存在する
- 試行毎にスクリーン上に出現するアイテムの個数が異なる
- 無作為に設定するパラメータが複数個ある
- 休憩が挿入される試行が条件数の倍数になっていない
まず1.と2.についてですが、画面上に刺激が大量に存在すると、ルーチン上に必要な個数のコンポーネントをひとつひとつ並べてパラメータを設定していかなければなりません。とても面倒な作業です。試行毎にアイテム数が異なる点も、真面目に作成しようとしたら第9章のテクニックを用いてアイテム数5個のルーチン、10個のルーチン、15個のルーチンを使い分けなければいけません。大変な手間です。もっとも「真面目に作成しようとしたら」と断り書きを入れるということは抜け道があるのですが、それはこの後の解説で触れます。
続いて3.と4.ですが、これらはいずれも条件ファイルに関わる問題です。今までの章では、無作為に変化するパラメータは条件ファイルで値を設定してきました。条件ファイルを使う場合は、すべてのパラメータの「組み合わせ」を明示的に記述しなければいけません。今回の実験を今までの章のように条件ファイルで作成しようとすると、固視点の提示時間が3種類ありますので、12種類の刺激と掛け合わせて36条件の条件ファイルになります。この条件ファイルを使うと実現可能な試行数は36の倍数になりますが、240は36で割り切れませんので、この時点で全試行数を240試行にすることは不可能になってしまいました。固視点の提示時間を1.0秒と1.5秒の2種類に減らすと12種類の刺激との掛け合わせで24条件の条件ファイルとなり、240試行にすることが可能になります。しかし、今回の実験ではアイテムの位置もCの向きもすべて無作為なのです。どう工夫しても、これまでの章の条件ファイルと同様の考え方では、総試行数が240試行となる条件ファイルを作成することは出来ません。
なぜ今回の実験では、今までの章と同じ考え方ではうまくいかないのでしょうか。今までの章では、「無作為」という言葉を使う時に、それは「順番が無作為」というだけでどのパラメータ(の組み合わせ)を何試行行うかが決まっていました。ところが、今回の実験では、パラメータそのものを試行毎に無作為に決めようというのです。結果として全試行を通じて3種類の注視時間が選ばれた回数は均等にならないでしょうが、本当に「無作為に」有限回数の選択をしたのであれば、むしろ回数が均等にならないことがある方が普通です。この種の「無作為さ」を実現する方法はBuilderには用意されていませんので、Codeコンポーネントの力を借りる必要があります。
この章の課題をBuilderで実現することの厄介さを何となく感じていただけましたでしょうか。筆者の個人的な考えでは、Builderに慣れていない初級から中級の方がこの章の実験をBuilderで作成するのであれば「すべての刺激を画像としてあらかじめ用意する」という方法を検討すべきだと思います。 図10.2 および 図10.3 に基づいて数百から数千枚程度の刺激画像ファイルを作成しておいて、その中から240枚の画像を各条件の試行数を満たすように無作為に抽出した条件ファイルを複数個準備しておいて、参加者毎にことなる条件ファイルを使用して実験を行うのです。しかし、本書はBuilderのさまざまなテクニックを紹介することが目的なので、Builder上で刺激を作成して実験を行う方法を考えたいと思います。
10.2. 実験の作成¶
実験の作成に入りましょう。まず前章までに解説済みのテクニックで作成できる部分を作成します。Builderで新規に実験を作成して以下の作業を行い、exp10proto.psyexpという名前で保存してください。
実験設定ダイアログ
- 「xlsx形式のデータを保存」をチェックする。
- 単位 をpixにする。
trialルーチン
最初から配置されているStaticコンポーネントの 名前 がISI、 開始 と 終了 がそれぞれ0.0と0.5になっていることを確認する(いずれも初期値)。
Codeコンポーネントをひとつ配置して、 名前 をcode_trialにする。今はコードを入力しない。
Textコンポーネントをひとつ配置して、以下のように設定する。
- 名前 をfixpointにする。
- 終了 をdelayにする。
- 文字の高さ $ を24にする。
- 文字列 に + と入力する。
Keyboardコンポーネントをひとつ配置して、以下のように設定する。
- 名前 をkey_resp_trialにする。
- 開始 をdelayに、 終了 を空白にする。
- Routineを終了 がチェックされていることを確認する。
- 検出するキー $ を’right’, ‘left’とする。
- 正答を記録 をチェックし、 正答 に$correctAnsと入力する。
Imageコンポーネントをひとつ配置して、以下のように設定する。
- 名前 をimage00にする。
- 開始 をdelayに、 終了 を空白にする。
- 画像 にimagefile[0]と入力し、「trialのISIの間に更新」設定する。
- 回転角度 $ にori[0]と入力し、「繰り返し毎に更新」に設定する。
- 位置 [x, y] $ にpos[0]と入力し、「繰り返し毎に更新」に設定する。
- サイズ [w, h] $ に[30, 30]と入力する。
restルーチン(作成する)
フローのtrialルーチンの直前に挿入する。
Codeコンポーネントをひとつ配置して、 名前 をcode_restにする。今はコードを入力しない。
Textコンポーネントをひとつ配置して、以下のように設定する。
- 名前 をtextRestにする。
- 終了 を空白にする。
- 文字の高さ $ を24にする。
- 文字列 に「準備が出来たらカーソルキーの左右どちらか一方を押してください」と入力する。
Keyboardコンポーネントをひとつ配置して、以下のように設定する。
- 名前 をkey_resp_restにする。
- 終了 を空白にする。
- Routineを終了 がチェックされていることを確認する。
- 検出するキー $ を’right’, ‘left’とする。
- 記録 を「なし」にする。
trialsループ(作成する)
- restルーチンとtrialルーチンを繰り返すように挿入する。
- 繰り返し回数 $ に20と入力する。
- 繰り返し条件 にexp10cnd.xlsxと入力する。先にexp10cnd.xlsxを作成してから「選択…」ボタンをクリックして選択するとよい。
exp10fi.xlsx(条件ファイル)
- numItems、firstItem、otherItems、correctAnsという名前のパラメータを定義する。
- numItemsは5、10、15の3種類、firstItemはo.png、c.pngの2種類、otherItemsもo.pngとc.pngの2種類の値をとる。これらの全ての組み合わせを入力する。パラメータ名を定義する行を除いて3×2×2=12行の条件ファイルとなる。
- firstItemとotherItemsが同じ行のcorrectAnsの列にleftと入力する。firstItemとotherItemsが異なる行のcorrectAnsの列にrightと入力する。
o.pngおよびc.png(刺激画像ファイル)
- 背景が透過した30×30pixのPNGファイルを作成し、o.pngという名前にする。o.pngには白色の円を描く。o.pngをc.pngという別名で保存し、円の中心右側の10pix分を消して切れ目を入れる。
最後に、restルーチンに配置してあるrest_codeの フレーム毎 に以下のコードを入力しておいてください。これは、条件数である12の倍数ではない「80試行毎の休憩」を実現するためのコードです。第9章で紹介したbreakによるルーチンのスキップが利用されています。
if trials.thisN % 80 != 0:
break
第9章の解説が済んでいなかったら、この80試行毎に休憩を挿入する方法も「難問」として挙げなければいけないところでした。念のためコードについても解説しておきますと、trials.thisNは0から始まってtrialsループが1回繰り返されるたびに1増加します。trials.thisNを80で割った剰余が0でない時はbreakするので、剰余が0となる実験開始直後、80試行終了後、160試行終了後のみrestルーチンがスキップされずに実行されます。よろしいでしょうか。それでは作業を進めましょう。まずはtrialルーチンに1個だけ配置してあるImageコンポーネントを15個まで増やす作業です。
10.3. テキストエディタを用いて多数のコンポーネントを追加しよう¶
今回の実験では、最大15個のアイテムをスクリーン上に提示するために、trialルーチンに15個のImageコンポーネントを配置しなければいけません。前節の作業でImageコンポーネントを配置して 名前 にimage00、 回転角度 $ にori[0]、 位置 [x, y] $ にpos[0]と入力しましたが、Imageコンポーネントを追加してこれらの値をimage01、ori[1]、pos[1]にし、さらに続いてImageコンポーネントを追加してimage02、ori[2]、pos[2]、…としていって、image14、ori[14]、pos[14]に到達するまで作業を繰り返さなければいけません。もちろん、 開始 や 終了 、 サイズ [w, h] $ の値の設定や、「trialのISIの間に更新」と「繰り返し毎に更新」の設定も忘れずに行わなければいけません。これはかなり面倒です。作業自体も面倒ですが、どれかひとつのコンポーネントで サイズ [w, h] $ の値を設定し忘れたりした場合に、ルーチンペイン上にずらっと並んだImageコンポーネントのどれを修正したらいいか探し出すのはうんざりするほど面倒です。この章では、もう最終章ということで「反則技」を紹介しておこうと思います。
ここで解説する方法を用いるには、UTF-8の文字コードとLFの改行コードのテキストファイルの編集に対応しているテキストエディタが必要です。UTF-8とLFの組み合わせはLinux系OSでは標準的なので、UbuntuなどのLinuxで作業している方は、標準でインストールされているテキストエディタ(geditなど)で問題なく編集できます。Microsoft WindowsやMacOS Xではオープンソースのテキストエディタをインストールすることで編集が可能になります。非常に多くのエディタがありますが、筆者が愛用しているのは以下のエディタです。
- サクラエディタ (Windows向け) http://sakura-editor.sourceforge.net/
- mi (MacOS X向け) http://www.mimikaki.net/
以下の解説では、サクラエディタの画面を例に用います。まず、作業に失敗した時のためにやり直しが出来るように、exp10proto.psyexpのコピーを作成してexp10.psyexpという名前にしておきましょう。以後の作業は、exp10.psyexpに対して行うものとします。
exp10.psyexpをテキストエディタで開くと、 図10.4 のようにXML形式というフォーマットで記述された実験の内容が表示されます。XML形式については XML形式による実験の表現 を参照してください。
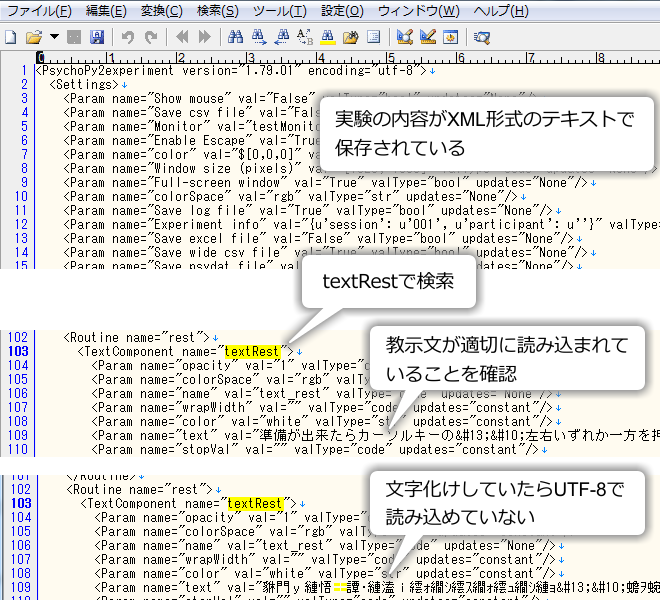
図10.4 exp10proto.psyexpをテキストエディタで開いた様子。textRestという文字列が見つかった数行下に教示文が適切に表示されていれば、正しい文字コード(UTF-8)で読み込めています。
textRestという文字列を検索すると、restルーチンに配置したtextRestの設定位置へ移動できます。textRestという文字列が見つかった数行下に教示文が適切に表示されていれば、正しい文字コード(UTF-8)で読み込めています。 図10.4 の一番下のように意味不明な記号や文字が並んでいる場合は、UTF-8で読み込めていません。このまま編集作業を続けると教示が失われてしまいますので、ファイルを開き直してください。どうしてもUTF-8で開けない場合は、一旦Builderに戻って日本語などの非ASCII文字を全て削除すれば文字化けは解消されます。exp10.psyexpの場合はtextRestの 文字列 に日本語の文字が入力されているので、ここを一旦空白にしておけば文字化けが解消されます。テキストエディタでの作業を終えてから、教示文を入力し直しましょう。
無事にテキストエディタでexp10.psyexpを開くことが出来たら、image00という文字列で検索してください。以下のような部分が見つかるはずです。
<ImageComponent name="image00">
<Param name="opacity" val="1" valType="code"…(略)
(中略)
<Param name="name" val="image00" valType="code" …(略)
(中略)
<Param name="pos" val="pos[0]" valType="code"…(略)
(中略)
<Param name="ori" val="ori[0]" valType="code"…(略)
(中略)
<Param name="image" val="$imagefile[0]" valType="str"…(略)
(中略)
</ImageComponent>
これがtrialルーチンに配置したImageコンポーネントの設定です。XMLをご存じない方でも、なんとなくBuilder上でのImageコンポーネントのプロパティ設定画面との対応が想像できるのではないでしょうか。この部分をコピー&ペーストしてimage00、pos[0]、ori[0]、imagefile[0]を書き換えれば、image01、image02、image03…をtrialルーチンに追加することが出来ます。
<ImageComponent name=”image00”>という行から、</ImageComponent>という行までを選択してコピーしてください。exp10.psyexpではImageコンポーネントはひとつしか配置されていないので間違えようがありませんが、同種類のコンポーネントが複数個配置されているpsyexpファイルでこのテクニックを使う場合のために、コピー範囲の判断方法を説明しておきます。psyexpファイルでは、コンポーネントやルーチンなどの要素が定義されている範囲が字下げで判断できるようになっています( 図10.5 )。Pythonのfor文やif文の文法と似ていますが、Pythonと違って最初に見つけた同じ字下げの行を要素に含む点に注意してください。コピーしたら、作業用に新しいテキストファイルを開いて14回繰り返して貼りつけてください。貼りつけたらexp10tmp.txtという名前で保存しておきましょう。
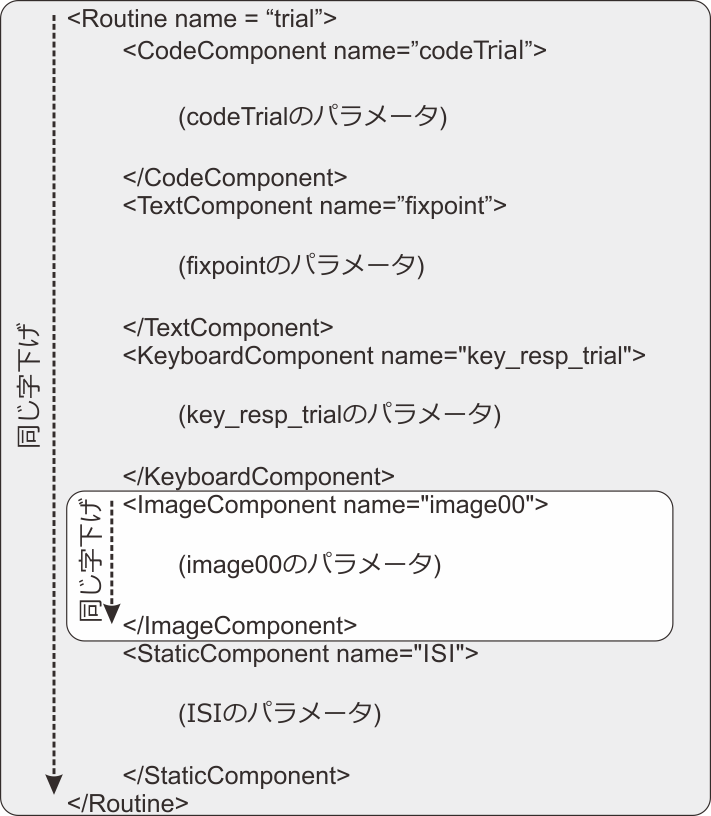
図10.5 コピー範囲の判断。白い四角形の部分がコピーする範囲です。
exp10tmp.txtを保存したら、exp10tmp.txtのパラメータの設定を上から順番に書き換えていきましょう( 図10.6 )。ちょっと面倒ですが、Builder上で14個のImageコンポーネントを追加することを考えたら楽なものだと思って頑張ってください。
- image00をimage01、image02、…、image14に書き換える。ひとつのImageコンポーネントに付きimage00は二カ所あるので注意すること。
- pos[0]をpos[1]、pos[2]、…、pos[14]に書き換える。
- ori[0]をori[1]、ori[2]、…、ori[14]に書き換える。
- imagefile[0]をimagefile[1]、imagefile[2]、…、imagefile[14]に書き換える。
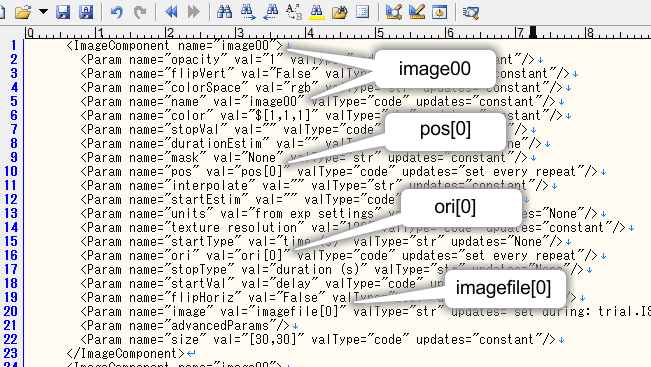
図10.6 Imageコンポーネントの設定を書き換えます。
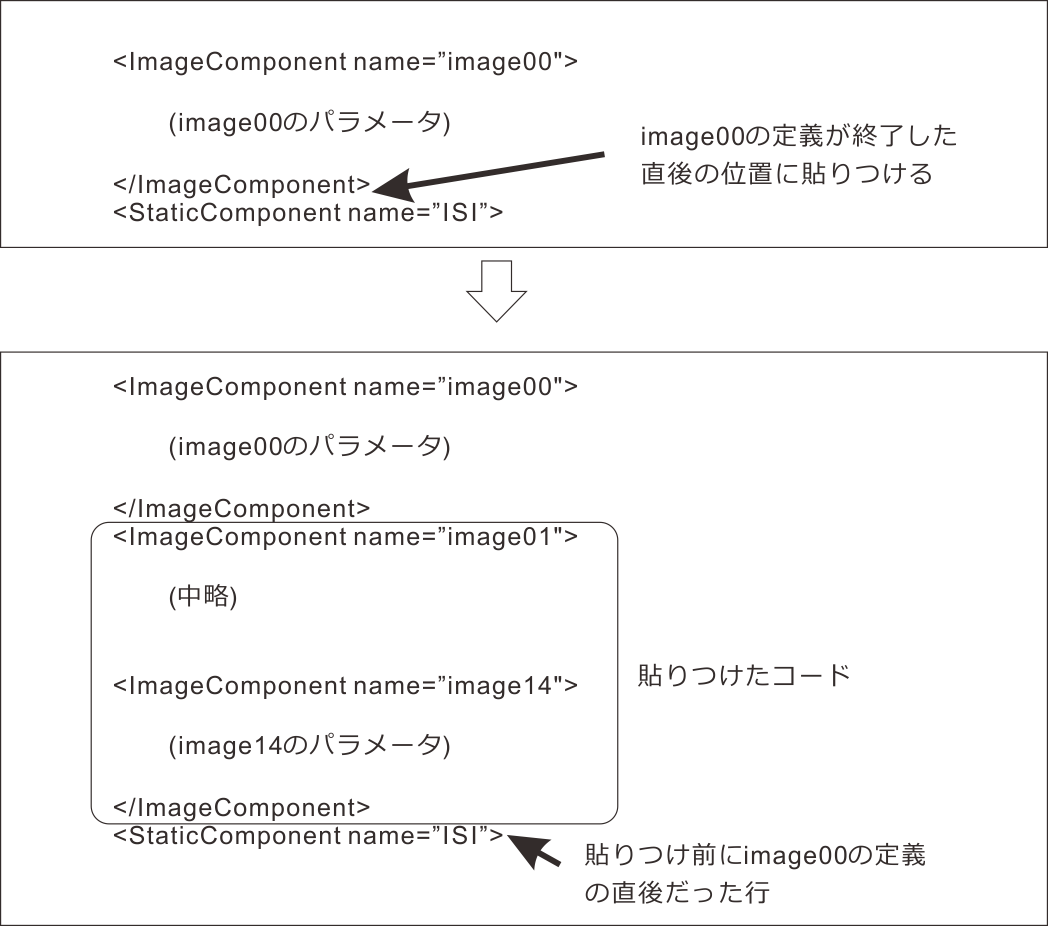
図10.7 編集したコードの貼り付け。元ファイルのimage00の定義の直後へ挿入するように貼りつけます。
書き換えが終了したら、exp10tmp.txtを元のexp10.psyexpに貼りつけます。貼り付ける場所は、image00の定義のすぐ後ろです( 図10.7 )。貼りつけたらexp10.psyexpを保存して、Builderから開いてみてください。 図10.8 のように、trialルーチンにimage00からimage14までの15個のImageコンポーネントが配置されているはずです。適当にいずれかのImageコンポーネントをクリックして、image03ならパラメータがpos[3]、ori[3]、imagefile[3]といった具合に 名前 の番号とパラメータに含まれるリストのインデックスの値が一致することを確認してください。成功したら、もうexp10tmp.txtは削除していただいても構いません。失敗した場合は、exp10tmp.txtに誤りがないか、exp10.psyexpへのコピー位置が正しいかをよく確認して作業をやりなおしてください。
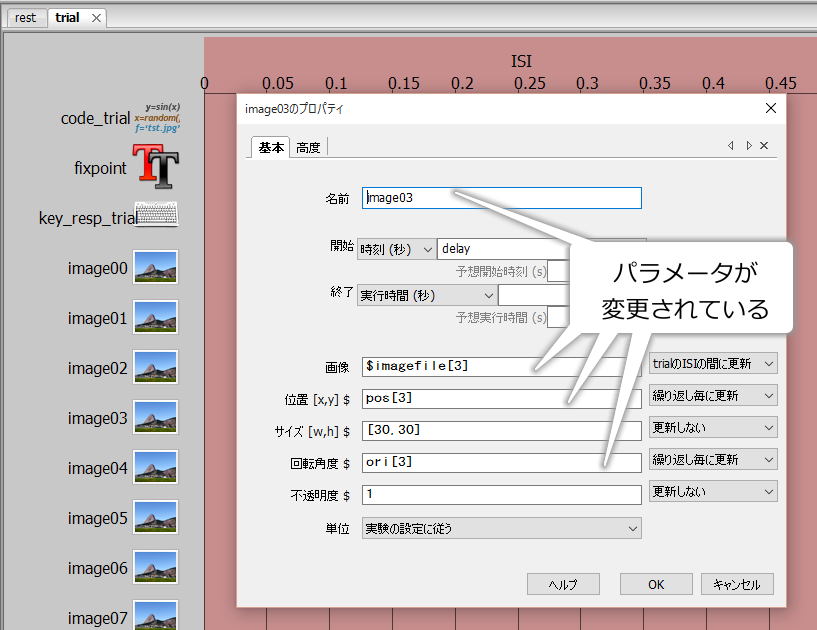
図10.8 編集後のexp10.psyexpをBuilderで開くとテキストエディタで追加したImageコンポーネントがtrialルーチンに表示されます。
これで15個のImageコンポーネントを追加するという問題をクリアすることが出来ました。恐らくPythonのスクリプトを書ける方は「ここまでするくらいなら全部Coderでコードを書いた方がいい」と思われるかも知れませんが、psyexpファイルの仕組みを知っておくといろいろと便利なこともあります。例えば第3章で「PsychoPy 1.84.0以前のBuilderにはルーチン名を変更する機能がない」と書きましたが、psyexpファイルを直接編集すれば簡単にルーチン名の変更ができます。詳しくは PsychoPy 1.84.0より前のPsychoPyでルーチン名を変更する をご覧ください。
それでは続いて、試行毎に無作為にアイテムの位置と固視点の提示時間を変更する方法を考えましょう。
- チェックリスト
- テキストエディタを用いて適切な改行コード、文字コードでpsyexpファイルを開くことが出来る。
- psyexpファイルをテキストエディタで開いて 名前 の値を検索して、コンポーネントのパラメータの定義を探し出すことが出来る。
- psyexpファイルをテキストエディタで編集して、コンポーネントのパラメータを変更することが出来る。
- psyexpファイルをテキストエディタで編集して、Builderで配置したコンポーネントをコピーして個数を増やすことが出来る。
10.4. Codeコンポーネントを使って無作為に固視点の提示時間を選択しよう¶
これで必要なコンポーネントをすべてルーチン上に配置することが出来ましたので、コードを入力していきましょう。以下の処理をコードで実現する必要があります。
- trialルーチンで使われている変数delayの値を決定する。固視点の 開始 が0で 終了 がdelayに設定され、image00からimage14の 開始 がdelayに設定されているので、固視点が出現したdelay秒後に固視点が消失して代わりにimage00からimage14が提示される。
- ori[0]からori[14]の値を決定する。値は試行毎に0、90、180、270から無作為に選択する。
- pos[0]からpos[14]の値を決定する。値は試行毎に 図10.3 に示したグリッドから重複がないように無作為に選ぶ。
- imagefile[0]からimagefile[14]の値を決定する。この値の決め方については後述する。
これらの問題はいずれも「無作為に選択する」という点で共通しているので、同じ方法で解決できます。しかし、delayの決定以外は「アイテム数が5個、10個、15個と変化することにどう対応するか」という問題と併せて考えないといけないので、次節でまとめて考えることにしましょう。まずはdelayの問題を解決します。
無作為に値を選択するには、Builderが内部で用意している乱数関数( 表10.1 )を用います。使い方は非常に単純で、randint(0,5)と書けば0から4の整数の一様乱数からサンプルをひとつ得ることが出来ます。引数high「未満」ですから5を含まない点に注意してください。同様に、normal(50, 10)と書けば平均値50、標準偏差10の正規乱数からサンプルをひとつ得ることが出来ます。引数sizeは、randint(0, 5, size=3)のように使用します。この例の場合、戻り値は[0, 2, 1]といった具合に0から4の整数の一様乱数からサンプルを3つ並べたシーケンス型データが得られます。正確に書くとこの戻り値はnumpy.ndarrayクラスのインスタンスなのですが、numpy.ndarrayについて説明すると脱線が長くなるので numpy.ndarray型について を参照してください。
| random(size = None) | 0.0以上1.0未満の一様乱数のサンプルを返す。sizeがNoneの時(初期値)にはひとつのサンプルを、自然数の場合にはsize個のサンプルを返す。 |
| randint(low, high, size=None) | low以上high未満の範囲の整数の一様乱数のサンプルを返す。lowとhighは整数でなければならない。highがNoneの時には0以上low未満の範囲と見なされる。sizeの働きはrandom( )と同様。 |
| normal(loc=0.0, scale=1.0, size=None) | 正規分布に従う乱数のサンプルを返す。locは平均値、scaleは標準偏差に対応する。sizeの働きはrandom( )と同様。 |
| shuffle(x) | リストなどの要素を変更可能なシーケンス型データの要素を無作為に並べ替える。戻り値はない。xの元の順序は失われてしまう点に注意。 |
さて、今回の実験のように、複数個の選択肢からひとつを無作為に選びだすという用途には、randint( )が便利です。delayの値は1.0、1.5、2.0の3通りです。randint(0, 3)とすれば戻り値として0、1、2の乱数が得られますから、戻り値に0.5を掛ければ0.0、0.5、1.0の乱数が得られます。ここへさらに1.0を加えると、1.0、1.5、2.0の乱数が得られます。従って、以下のコードでdelayの値に1.0、1.5、2.0の中から無作為にひとつ選んで設定できます。
delay = randint(0, 3)*0.5 + 1.0
exp10.psyexpのtrialルーチンを開いて、codeTrialにこの式を入力しましょう。試行毎にdelayの値を変化させるのですから、入力すべき場所は Routine開始時 です。これでdelayの値については解決しました。
あまりにもあっさり解決してしまったので、無作為に値を選択する方法についてもう少し考えてみましょう。今回のdelayはrandint( )の戻り値から簡単な計算で得ることが出来ましたが、「u’一致’、u’不一致’のいずれか一方を無作為に選ぶ」という具合に計算で得ることが出来ない値から選択しないといけない場合はどうすればいいでしょうか。この章まで学んできた人ならピンと来るかもしれません。選択肢のリストを作成して、リストのインデックスにrandint( )の戻り値を使えばよいのです。変数tasktypeにu’一致’またはu’不一致’という文字列のいずれかを無作為に選んで設定するのであれば、例えば以下のようなコードで実現することが出来るでしょう。
tasklist = [u'一致', u'不一致']
tasktype = tasklist[ randint(0, 2) ]
変数tasklistは実験の最初に一回だけ作成すればよいので、Builderでこのコードを使用する場合はtasklist = [u’一致’, u’不一致’]は 実験開始時 に書いておいて、tasktype = tasklist[ randint(0, 2) ]を該当するルーチンの Routine開始時 に書くとよいでしょう。この方法はもちろん今回のdelayのように、数値をひとつ選択する場合にも使えます。
delaylist = [1.0, 1.5, 2.0]
delay = delaylist[ randint(0, 3) ]
最初に紹介した、計算によってdelayの値を得る方法の場合は、 Routine開始時 にだけコードを入力すれば済みますが、数か月後に自分が作成した実験を読み直さないといけなくなったときなどに少々わかりにくいかもしれません。リストを用意する方法は、 実験開始時 と Routine開始時 にコードが分散するという欠点がありますが、後で読み返す時には「ああ、delaylistから値を一つ無作為に取り出しているんだな」という事がわかりやすいかも知れません。どちらの方法を使っていただいても結構です。 以上でこの節の解説は終わりですが、最後にひとつ補足しておきます。web上でPythonの乱数について検索すると、randint(low, high)は「low以上high『以下』の値を返す」と書かれている資料がヒットするかもしれません。非常に紛らわしいのですが、このような資料で紹介されているrandint( )と、Builderが内部で参照している乱数関数のrandint( )とは全く別の関数です。「low以上high『以下』の値を返す」randint( )は、Pythonのrandomモジュールからimportされています。ですから、モジュール名を省略せずに書けばrandom.randint( )という関数です。一方、Builderが内部で準備しているrandint( )はnumpyというパッケージのサブモジュールnumpy.randomからimportされています。省略せずに書けばnumpy.random.randint( )です。気を付けてください。
- チェックリスト
- low以上high未満の整数を範囲とする一様乱数のサンプルをひとつ得るコードを書くことが出来る。(low、highは整数)
- 整数の一様乱数を用いて、試行毎に複数の値のリストからひとつの値を無作為に選択するコードを書くことが出来る。
10.5. Codeコンポーネントを使って無作為にアイテムの各パラメータを決めよう¶
delayの問題が解決したので、続いてアイテムの個数、種類、位置、回転角度を決める方法について考えましょう。一度にすべてのパラメータについて考えるのは大変なので、まずは「アイテムが15個の場合」に限定して考えます。
まず、簡単に解決できるのが回転角度の決定です。15個のImageコンポーネントの 回転角度 $ は、ori[0]、ori[1]、…、ori[14]というリストの値がすでに入力されています。ですから、oriという要素数15のリストを作成して、要素に0、90、180、270のいずれかの値を無作為に割り当てればよいだけです。どうせ毎試行oriの値は更新するので、最初にoriを作成する時には値は何を設定しても構いません。例えば以下のように0を15個並べたリストを作成してもよいでしょう。
ori = [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
別にこのコードで全く問題はないのですが、もし要素数が100個必要になった場合、100個も0を並べたリストを入力するのは面倒です。そのような時に便利な関数がrange( )です。range( )は1個から3個の整数を引数として取ることが出来ます。引数が1個の場合は、0から引数より1小さい整数までを並べたリストが得られます。例えばrange(15)とした場合、以下のリストが戻り値として得られます。
[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14]
引数が2個(x, yとします)の場合は、xからy-1までの整数を並べたリストが得られます。例えばrange(10, 15)を実行すると以下のリストが得られます。
[10,11,12,13,14]
引数が3個の場合、整数が1ずつ増加するのではなく3個目の引数の値ずつ増加します。range(0,15,3)を実行すると、以下のように3ずつ増加する整数のリストが得られます。15は含まない点に注意してください。
[0,3,6,9,12]
このrange( )とfor文を組み合わせると、要素数が等しい複数のリストに対してまとめて処理を行うコードが簡単に書けます。まず、range( )とfor文を組み合わせて0が15個並んだリストを作成してみましょう。
ori = [ ]
for i in range(15):
ori.append(0)
これで0が15個並んだリストが変数oriに格納されましたが、これだけでしたら先ほどのようにずらっと0を15個並べたほうが楽だと思われるかもしれませんね。ここへ、各アイテムの種類(OかCか)を格納する変数imagefileを準備する処理も組み込んでみましょう。imagefileはImageコンポーネントので使用されますので、その要素は画像ファイル名でなければいけません。こちらも試行毎に値を変更するのでとりあえずOとCのどちらを設定しておいても構いません。とりあえずOで初期化しておくことにしましょう。Oの刺激はo.pngと画像ファイルに対応していますので、’o.png’という文字列を15個並べたリストを作成する必要があります。oriを作成した時と同じ要領で考えると、以下のコードで実現できます。
ori = [ ]
imagefile = [ ]
for i in range(15):
ori.append(0)
imagefile.append('o.png')
刺激の位置を格納する変数posの準備もここへ組み込むことが出来ます。要素は 位置 [x, y] $ で使用するので、要素数2のリスト[0, 0]で初期化しておきましょう。
ori = [ ]
imagefile = [ ]
pos = [ ]
for i in range(15):
ori.append(0)
imagefile.append('o.png')
pos.append([0, 0])
以上でori、imagefile、posの準備は完了です。このコードは実験開始時に一回実行すればよいので、 実験開始時 に入力しておきましょう。
変数の準備が出来たので、続いて各試行の最初に無作為にこれらの変数の値を決定するコードを作成しましょう。まず、oriについてはdelayと同じ方法が使えます。Randint(0, 4)で0から3の整数の乱数を得て、90倍すれば0、90、180、270の乱数が得られますので、for文でori[0]からori[14]に代入すればいいでしょう。この方法では回転させる必要がないOも回転させてしまいますが、Oは回転させても見た目が同じなので実質的に問題とはなりません。以下のコードを Routine開始時 に入力して下さい。
for i in range(15):
ori[i] = 90*randint(0,4)
続いてimagefileの設定ですが、こちらは少し解説が必要です。すべてOの条件、すべてCの条件、Oの中にひとつだけCの条件、Cの中にひとつだけOの条件の4条件があるのでした。そして、条件ファイルを確認にはfirstItemとotherItemsというパラメータが定義されています。firstItemはimagefile[0]、otherItemsはimagefile[1]からimagefile[14]に設定することを想定しています。 図10.9 をご覧ください。firstItemとotherItemsがともにo.pngであれば「すべてO」の条件に、ともにc.pngであれば「すべてP」の条件になります。同様にfirstItemがc.pngでotherItemsがo.pngであれば「Oの中にひとつだけC」、firstItemgがo.pngでotherItemsがc.pngであれば「Cの中にひとつだけO」になります。「必ずimage00ターゲットになっても問題はないの?」と思われる方がおられるかも知れませんが、試行毎に位置を無作為に決定するので問題ありません。
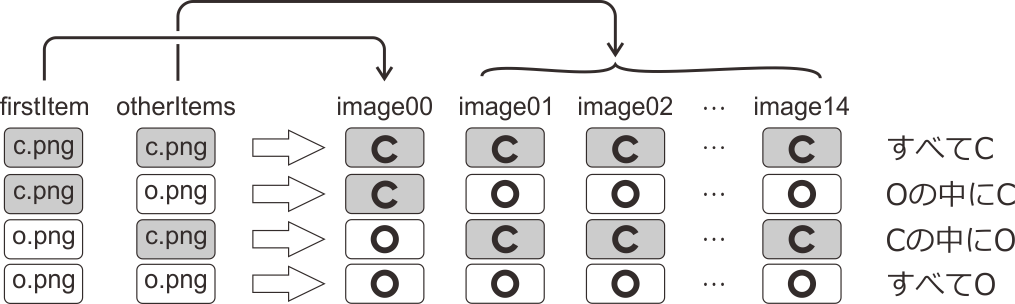
図10.9 firstItemとotherItemsのパラメータ値と刺激条件との対応。
先ほど Routine開始時 に入力したoriを更新するfor文に、imagefileを更新するコードを追加しましょう。変数iの値が0の時にはimagefile[i]にfirstItemの値を設定し、iの値が0以外の時にはimagefile[i]にotherItemsの値を設定します。
for i in range(15):
ori[i] = 90*randint(0,4)
if i==0:
imagefile[i] = firstItem
else:
imagefile[i] = otherItems
ori、imagefileの更新が出来たので、あとはアイテムの位置に対応する変数posの更新です。posは「無作為に値を決定する」という点ではoriと同じですが、重要な違いがあります。oriはアイテム間で値が重複しても構いません。つまり、例えば同時に回転角度が90度のアイテムが複数個存在しても構いません。一方、posはアイテム間で値が重複するとアイテムが重なってしまいますので、値の重複は許されません。次の節では、posの値を決定する方法を考えます。
- チェックリスト
- range( )を用いて、0からn (n>0)までの整数を並べたリストを作成することができる。
- range( )を用いて、mからn (n>m)までの整数を並べたリストを作成することができる。
- range( )を用いて、mからnまで、sの間隔で整数を並べたリストを作成することができる。ただしm、nは互いに異なる整数、sは非0の整数である。
10.6. 無作為に重複なく選択しよう¶
それでは改めて、posの値の決定方法を考えましょう。posの候補となる値は 図10.3 に示したグリッドの座標で、36個あります。これら36個の値の中から15個を重複なく無作為に選択しなければいけません。心理学実験においては、この例のように複数個の値を重複なく無作為に選択しなければいけないことがよくあります。このようなときは、「無作為に選択する」のではなく「無作為に並べ替える」という方法が有効です。
まず、36個の座標値をすべて並べたリストを作成してposlistという変数に格納しておきましょう。以下のようにfor文を重ねると簡単に作成できます。appendしている行の式については、グリッドの間隔が100pixで一番左下の座標が[-250, -250]だったことを思い出してください。この多重for文を実行したときにposlistに値が追加されていく様子を 図10.10 に示しましたので、多重for文の動作がイメージしにくい方は参考にしてください。この多重for文をcodeTrialの 実験開始時 に追加してください。
poslist = [ ]
for pos_y in range(6):
for pos_x in range(6):
poslist.append([100*pos_x-250, 100*pos_y-250])

図10.10 多重for文による座標値リストの作成。
続いて、作成したposlistの要素を無作為な順序に並び替えます。並び替えには 表10.1 で紹介したshuffle( )を用います。shuffle( )は引数として受け取ったリストの要素の順番を無作為に並び替えます。戻り値は返さないので、ただshuffle(poslist)と書けばposlistの要素を並び替えることが出来ます。試行毎にアイテムの位置を変更したいので、 Routine開始時 に記入してください。
さて、ここからがポイントです。poslistの要素はルーチンの開始時に無作為に並び替えられているのですから、poslistの先頭から順番に15個の要素を取りだせば、poslistの中から重複なしに無作為に15個の要素を取り出したことになります。従って、以下のコードでpos[0]からpos[14]に重複なく無作為に位置を割り当てることが出来るはずです。
for i in range(15):
pos[i] = poslist[i]
for i in range(15):という繰り返しは先ほどoriとimagefileの値を設定する時にも使用したのですから、以下のようにoriとimagefileの設定を合わせて行うことが出来ます。確認のため、delayの設定やshuffleも含めた Routine開始時 全体のコードを示しておきます。
delay = 0.5*(randint(0,3))+1
shuffle(poslist)
for i in range(15):
ori[i] = 90*randint(0,4)
pos[i] = poslist[i]
if i==0:
imagefile[i] = firstItem
else:
imagefile[i] = otherItems
これで「アイテム数が15個の場合」に限定した条件での実験が完成しました。一度exp10.psyexpを保存して実行してみましょう。常にアイテムが15個提示されてしまいますが、アイテムの位置や向きが試行毎に無作為に変化していることが確認できます。これで残りはアイテムの個数をnumItemsパラメータの値に従って変化させるだけです。
- チェックリスト
- リストの要素を無作為に並べ替えることが出来る。
- m個の要素を持つリストから、n個の要素(m>n)を重複なく無作為に抽出することが出来る。
10.7. アイテムの個数を可変にしよう¶
いよいよ最終段階、numItemsの値に従って試行毎にアイテム数を変化させる問題に取り組みましょう。いろいろな方法が考えられるのですが、ここでは簡単に実現できる「スクリーン外にアイテムを配置する」という方法を紹介します。今まで自分で実験を作成していて、刺激の単位がnormになっているのにpixのつもりで 位置 [x, y] $ に[500,0]などと指定して、刺激がスクリーンに描画されずに困ったことはないでしょうか。スクリーンの上下左右の限界から大きくはみ出た位置を指定してもエラーにならないせいでこういった困ったことが生じるのですが、今回はこれがエラーにならない事を逆手に取ります。 実験開始時 入力済みのコードのうち、アイテムの位置を決定する処理だけを抜き出してみましょう。
for i in range(15):
pos[i] = poslist[i]
ここへif文を追加して、iがnumItems未満の時は上記と同様の処理、iがnumItems以上の時はスクリーンの描画範囲を超えた位置を設定する処理を行うように変更します。
for i in range(15):
if i<numItems:
pos[i] = poslist[i]
else:
pos[i] = [10000, 10000]
if文の条件式がi<numItems であって、i<=numItemsではないことに注意してください。Pythonにおいてリストのインデックスは0から数えますので、5個のアイテムを表示するときには0、1、2、3、4番目の合計5個のアイテムにposlistの値を設定する必要があります。同様に、n個のアイテムを表示するためには0からn-1番目までのアイテムにposlistの値を設定しなければいけません。if文の条件式がi<=numItemsだと、0からnumItems番目までのnumItems+1個のアイテムにposlistの値が設定されてしまいます。
今回の例では、スクリーン外に置いて描画しないようにしたいアイテムに[10000, 10000]という位置を指定しています。時代と共にモニターの高解像度化が進んでいますが、スクリーン中央から右に10000ピクセル、上に10000ピクセルの位置の刺激が描画出来るモニターが登場するのはまだまだ先のことでしょう。何より、今回の実験は単位をpixにして作成していますので、[10000, 10000]が描画範囲に含まれるほどの高解像度モニターでこの章の実験を実行すると、刺激が小さすぎてまともな実験にならないでしょう。
なお、アイテムを描画しないようにさせるには、今回のようにスクリーンの描画範囲外の位置を指定するという方法の他にも、不透明度 $ を0.0にして完全な透明にしてしまうという方法もあります。ただし、透明化する方法の場合は、あくまで描画されていないだけでPsychoPyにとってはその位置に刺激があると認識されますので、第8章で紹介したcontains( )やoverlaps( )を使う時に注意する必要があります。刺激がそこに存在していないように見えるのに、マウスカーソルが「刺激の上に重なっている」と判定されてしまうなどの恐れがあるからです。もっとも、この問題ですら「実験参加者がスクリーン上のある領域にマウスカーソルを置いているか否か、参加者に悟られないように記録する」という用途にも使えますので、一概に不備だとは言えません。こういった一見不備に思える現象を積極的に利用することによって、Builderで実現できる実験の幅は飛躍的に広がります。ぜひ、いろいろと工夫していただきたいと思います。
さて、上記のコードをtrialルーチンの 実験開始時 に組み込んだ、最終版のコードを以下に記します。pos[i]への代入部分が変化したことを確認してください。
delay = 0.5*(randint(0,3))+1
shuffle(poslist)
for i in range(15):
ori[i] = 90*randint(0,4)
if i<numItems:
pos[i] = poslist[i]
else:
pos[i] = [10000, 10000]
if i==0:
imagefile[i] = firstItem
else:
imagefile[i] = otherItems
exp10.psyexpに上記の変更を加えたら、exp10.psyexpを保存して実行してみましょう。今度は試行毎に無作為な順番にアイテム数が5個、10個、15個と変化することを確認してください。十数試行ほどスクリーンに描画されたアイテム数をメモしてEscapeキーを押して実験を中断し、描画されたアイテム数とtrial-by-trial記録ファイルに出力されたnumItemsの値が一致していることも確認しましょう。これで今回の目標はすべて達成出来ました。
最後に、後の分析でアイテム位置の情報が必要になった場合に備えて、アイテム位置を保持している変数poslistの値を実験記録ファイルに出力する処理を付け加えておきましょう。独自の変数の値を出力する方法についてはすでに第7章で解説しましたので、出力自体はもう皆さん解説なしで出来ると思います。ただ、poslistは要素数36のリストである一方、後の分析で実際に必要となる可能性がある要素は実際にスクリーン上に提示された刺激の位置に対応する要素のみです。言い換えると、各試行で先頭からnumItems個の要素のみが必要です。何の工夫もせずにposlistをaddData( )メソッドに渡してしまうと、36個全部が出力されてしまうため、分析時に不必要な値を除去しなければならず、非常に無駄です。必要な値だけを抜き出して出力するのが理想的です。
for文を用いると、リストの先頭からnumItems個の要素を取り出したリストを作成するのは簡単です。例えば以下のコードのようにすれば変数displayed Posに実際に提示に利用された位置をまとめることが出来るでしょう。
displayedPos = []
for i in range(numItems):
displayedPos.append(poslist[i])
if文やfor文の利用はプログラミングの基本中の基本なので、こういったコードがぱっと頭に浮かぶようにしっかりとこれらの文に慣れて欲しいと思います。しかし、今回の用途に関してはPythonにスライスと呼ばれる非常に便利な機能がありますので、そちらもぜひ覚えて欲しいと思います。
スライスとは、リストやタプルなどのシーケンス型のデータから、連続する要素を抜き出す演算です。シーケンス型データが格納された変数varに対してvar[a : b]の書式で用い、インデックスaからインデックスbの間に含まれる要素を抜き出したリストを返します。aとbの間の記号は半角のコロンです。第8章で用いたリストの例をもう一度使って解説しましょう。 図10.11 例1をご覧ください。[100, 200, 300, 400, 500, 600]というリストを格納した変数varがあります。正のインデックスは、先頭から順番にそれぞれの要素の「前」にあると考えます。var[1:4]と書くと、インデックス1からインデックス4までの間の要素を取り出すのですから、[200, 300, 400]が得られます。初心者の方によくある勘違いに、スライスを「a番目の要素からb番目の要素を抜き出す」と考えてしまうというものがあります。「var[1]が200、var[4]が500ですから、var[1:4]は[200, 300, 400, 500]じゃないの?」というのがこの勘違いの典型です。飽くまで4というインデックスは500の前にあり、var[1:4]というスライスは「インデックス1からインデックス4までの間の要素を抜き出す」のですから、500は含まれません。
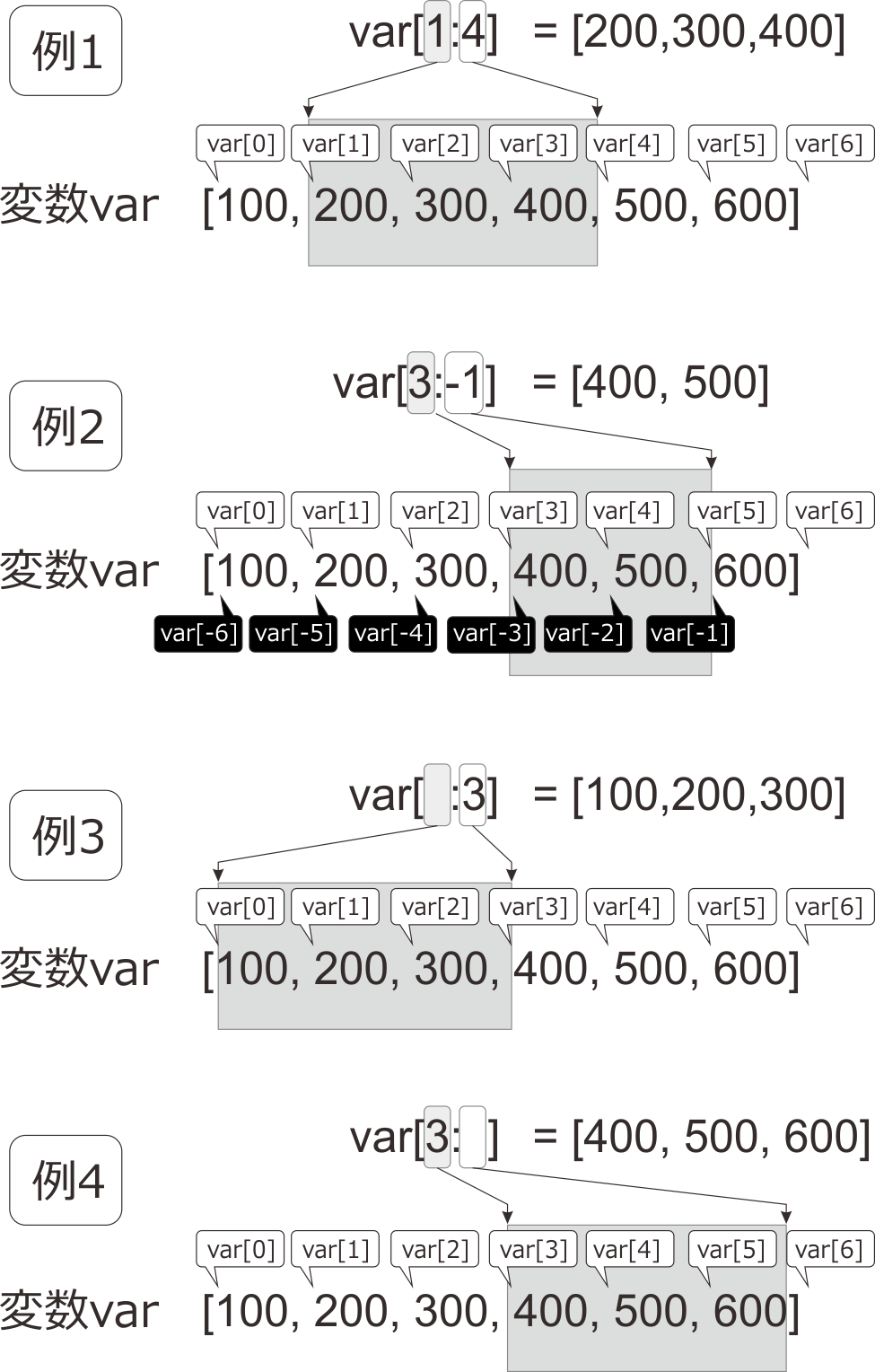
図10.11 スライスによるリスト要素の抽出。var[a:b]と書くと、変数varのインデックスaからインデックスbの間にある要素を抜き出します。aが省略されたときは先頭が、bが省略されたときは末尾が指定されたものとします。
リストから要素をひとつ取り出す時に負のインデックスを利用できたのと同様に、スライスでも負のインデックスを用いることが出来ます( 図10.11 例2)。正と負のインデックスを混ぜて使うことも出来ます。ただし、var[a:b]のaの方がbよりもリストの前方でなければいけません。 図10.11 例3つめの例のように、aが省略された時には、先頭から抜き出されます。 図10.11 例4のようにbが省略された時には、末尾までを抜き出します。
このスライスを利用すれば、poslistから実験記録ファイルに出力すべき要素を抜き出したリストを簡単に作ることが出来ます。poslistの先頭からnumItems個の要素を刺激提示に使ったのですから、poslist[:numItems]とすればよいだけです(コロンの前は省略している点に注意)。このリストを実際に実験記録ファイルに出力するコードを書くのは練習問題としましょう。
- チェックリスト
- ルーチンに配置された視覚刺激コンポーネントをスクリーン上に描画させないようにすることが出来る。
- スライスを用いて、あるリストから連続する要素を抽出したリストを作り出すことが出来る。
- リストの先頭から要素を抽出する場合のスライスの省略記法を用いることが出来る。
- リストの末尾までの要素を抽出する場合のスライスの省略記法を用いることが出来る。
10.8. 練習問題:透明化によるアイテム数変更と無作為な位置の調整をおこなおう¶
exp10.psyexpを改造して、この章の解説で出てきた二つのテクニックを実際に試してみてください。さらに、特にアイテム数が15個の時に、アイテムが無作為に配置されているというよりは整然と並んでいるように見えてしまうことを防ぐために、アイテムの位置を無作為に上下にずらす処理も追加してください。
- 不透明度$ を0.0にすることによってnumItems個のアイテムがスクリーンに描画されるようする。
- アイテムの位置を実験記録ファイルに出力するコードを完成させる。
- アイテムの位置を、変数posによって指定された位置から上下方向、左右方向ともに-15、-5、5または15pixずらす。ずらす量は試行毎、アイテム毎、方向毎に無作為に決定する。
10.9. この章のトピックス¶
10.9.1. XML形式による実験の表現¶
XMLとはExtensible Markup Languageの略で、マークアップ言語と呼ばれる言語のひとつです。タグと呼ばれる記号を用いて文書やデータの構造を記述することが出来ます。インターネットのwebページ等を作成したことがある人はHTMLをご存知のことと思います。XMLのタグはHTMLと似ていますが、HTMLと異なり自由にタグを定義して使用することが出来ます。
XMLの詳細については文献が大量にありますのでそちらを参照していただくとして、psyexpファイルを読むのに最小限必要なことだけを解説します。XML文書において、半角のアングルブラケット(山括弧:< >)で囲まれた文字列を「タグ」と呼びます。例えば<Routine>はタグで、Routineというのがタグの名前です。タグは必ず「開始タグ」と「終了タグ」を組み合わせて使用します。Routinの開始タグは<Routine>、終了タグは</Routine>といった具合に、終了タグにはタグ名の前に/が付きます。なお、<Routine/>という具合にタグ名の最後に/が付いているものを「空要素タグ」と呼びます。空要素タグについては後で説明します。
タグの中に、タグ名に続いてPythonにおける変数の代入のような記述が続けて書かれている場合があります。具体的には<Routine name=”trial”>といった具合です。この例において、name=”trial”をRoutineタグの「属性」と呼びます。nameが属性の名前で、”trial”がその値です。
タグは、開始タグと終了タグの間に他のタグを含むことが出来ます。以下の例では、Routineタグの間にCodeComponentというタグが含まれています。この例において、RoutineタグはCodeComponentタグの「親」、CodeComponentタグはRoutineタグの「子」と呼びます。XML文書では、このようにタグを入れ子構造にして、さまざまなデータや文書の構造を記述します。なお、Builderが作るXMLファイルはPythonのコードのように字下げされていますが、Pythonと異なり字下げは必須ではありません。
<Routine name="trial">
<CodeComponent name="code_trial">
</CodeComponent>
</Routine>
exp10proto.psyexpのRoutineタグを眺めていると、その要素としてルーチン内に配置したコンポーネントに対応するタグが並んでいることがわかると思います。さらにコンポーネントに対応するタグの要素を確認すると、先ほど述べた「空要素タグ」が見つかります。以下はその例です。
<Param name=”opacity” val=”1” valType=”code” updates=”constant”/>
空要素タグは、子となるタグを持ちません。空要素タグは他のタグを挟み込む必要がないので、単独で使用します。
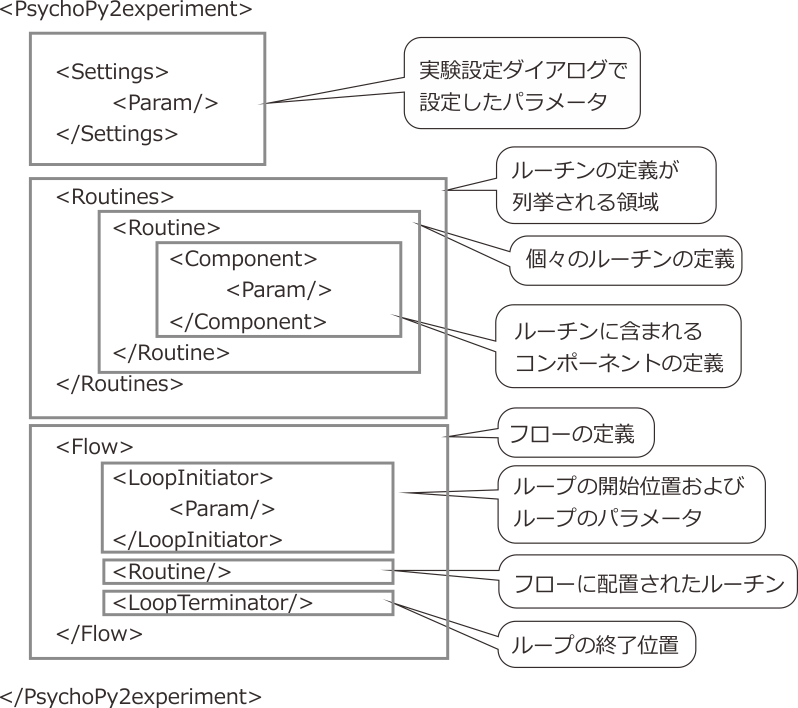
図10.12 psyexpファイルの構造
以上の点を踏まえたうえで、 図10.12 をご覧ください。 図10.12 はpsyexpファイルの構造を示しています。Builderの実験はPsychoPy2experimentというタグで表現されます。PsychoPy2experimentはSettings、Routines、Flowという要素を持ちます。Settingsには実験設定ダイアログで設定したパラメータが記述されています。Routinesは、実験で使用されるルーチンの定義であるRoutineを要素として持っています。 図10.12 ではひとつしかRoutineが描かれていませんが、実験でn個のルーチンを定義していればn個のRoutineがここに列挙されます。
個々のRoutineは、対応するルーチンに配置されているコンポーネントを定義するタグを要素として持っています。 図10.12 ではComponentsという名前のタグとして書いてありますが、すでに 図10.4 や 図10.5 で見たように、Imageコンポーネントに対応するタグはImageComponent、Keyboardコンポーネントに対応するタグはKeyboardComponentという具合に各コンポーネントに対応するタグが用意されています。本文ではtrialルーチンに配置されていたImageComponentをコピーして貼り付けることによって、Imageコンポーネントの個数を増やしました。 図10.5 や 図10.7 を見て、コピー範囲と貼り付け位置がタグの入れ子構造を壊さないようになっていることを確認してください。
Flowには、実験のフローがXMLで表現されています。Flowの子要素としてRoutineが配置されている場合は、フローの該当する位置にルーチンが配置されていることを示しています。ループの開始点と終了点はそれぞれLoopInitiatorとLoopTerminatorというタグで示されています。多重ループの実験などを適当に作成して(あるいは第4章で作成したpsyexpファイルを持ってきて)psyexpファイルの中を確認すると、フローとこれらのタグの関係がよくわかります。
10.9.2. PsychoPy 1.84.0より前のPsychoPyでルーチン名を変更する¶
本文中で述べたとおり、バージョン1.84.0より前のBuilderにはルーチン名を変更する機能がありません。しかし、実験を保存したpsyexpファイルを直接テキストエディタで編集すれば変更することは可能です。上級者向けのテクニックですので、初心者の方はとりあえず読み流していただくだけで結構です。
psyexpファイルはLFを改行コードとするテキストファイルです。LFは一般にUnixで用いられる改行コードで、Microsoft Windowsなどの他のOSで作業している方は、LFを改行コードとして認識できるテキストエディタを使う必要があります。図 3 34はこの章で作成したexp03.pyexpを開いた様子です。実験の内容がXML(Extensible Markup Language)という言語を用いて記述されています(詳しくは第10章参照)。<Routines>がルーチンの定義開始を示すタグで、この中に<Routine name=”xxx”>という形でルーチン名が定義されています。xxxがルーチン名ですので、この行を探してxxxを書きかえて保存した後にBuilderで開けばルーチン名が変更されます。ただし、名前を変更したルーチンがすでにフローに挿入されている場合は、フローの対応する部分も変更しておかないとBuilderで開く際にエラーになります。フローの定義開始タグは<Frow>で、終了タグ</Frow>までの間に挿入されたルーチンが<Routine>タグで示されています。この中に名前を変更したいルーチンxxxに対応する<Routine name=”xxx”/>という行がありますので、xxxを新しいルーチン名に書き換えてください。
図 3 34 psyexpファイルの内容。2.と4.のname=”trial”をname=”testTrial”に書き換えてBuilderで開くとtrialルーチンの名前がtestTrialに変化しています。
10.9.3. numpy.ndarray型について¶
これまでの章ではずっと、刺激の位置(座標値)や大きさといった二次元の量を指定するためにリストを使用してきました。本書の用途のように静的な位置を表現するだけならリストで十分なのですが、座標値に対する演算を行おうとするとリストは非常に不便です。例えば[5,3]という座標値をX軸方向に1、Y軸方向に2移動させたい場合、ベクトルの演算をご存知の方は直感的には[5,3]+[1,2]と書きたくなるでしょう。しかし、Pythonにおけるリストは数値以外にも文字列なども要素になり得ますので、[5,3]+[1,2]をベクトルの和と解釈することにすると要素に数値以外の値があったときに演算が定義できなくなってしまいます。そのようなわけで、かどうかはわかりませんが、Pythonはリスト同士に対する+演算子はリストの結合として解釈します。つまり、[5,3]+[1,2]=[5,3,1,2]です。同様に、リストに対する数値の積は、ベクトルとスカラーの積ではなく、ベクトルの繰り返しとして解釈されます。[5,3] * 4でしたら[5,3]を4回繰り返したリストである[5,3,5,3,5,3,5,3]が得られます。
これでは本格的なベクトル演算を行う時に不便で仕方がないので、PythonではNumPyというパッケージが用意されています。NumPyを導入すると、直感的なベクトル演算が可能となります。NumPyにおける演算の基本となるのがnumpy.ndarray型のオブジェクトです。Builderではリストなどのデータをnumpy.ndarrayに変換するnumpy.asarrayという関数がasarrayという名前で利用できるように準備されています。asarrayを使うと、先ほどのようなベクトル風の演算が可能になります。
asarray([5,3]) + asarray([1,2]) → array([6,5])
asarray([5,3]) * 4 → array([20,12])
これらの演算で得られた戻り値もnumpy.ndarray型のオブジェクトです。numpy.ndarray型オブジェクトは、リストと同じように[ ]演算子で要素を取り出したり、スライスを適用したり、len( )で要素数を求めたりすることが出来ます。ですから、[ ]やlen( )に関しては今まで学んできたリストと全く同等に使えます。しかし、+演算子や*演算子を適用した時の働きがリストと異なります。違いを十分に理解できればasarray( )を使って積極的にnumpy.ndarrayの機能を活用していただければ良いのですが、区別に自信がない場合は使わない方がよいでしょう。