例題22-3:それってNumpyでいいよね(暴言)¶
A: さて、IPython Notebookの解説でずいぶん脱線してしまったが、今回こそpandasをゆるーく取り上げる。
B: pandasで検索したらパンダの画像がいっぱい出てきましたよ!かわいい!
A: …。(呆れ顔で)
B: なにか?
A: 前回あんな終わり方をしておいていきなりB君が復活していることといい、前回と同じ導入といい、本当に作者は何を考えているのか、いや何も考えていないのか…
B: (「余計なことを言うとAさんも危ないですよ?」と書いたメモをこっそり見せている)
A: あー、げほげほ。おほん。(気を取り直して)…パッケージの名前に凝るのはいいんだけど、あまり一般的な名刺と一致しないようにしてほしいよな。検索するのが大変だ。まあ一番検索するのがうっとおしいのはR!貴様だ!
B: ぐふふっ、子パンダかわいいなあ
A: B君がそういう趣味だとは知らなかった。今日のお題は別にかわいくない方のpandasだ。調べてみた感じ 無理やり感全開な略称 じゃないみたいだな。公式ページ( http://pandas.pydata.org )にはPython Data Analysis Libraryと見出しがついている。
B: で、何が出来るんですか?
A: まあいろんなことが出来るのだが…。とりあえず学会とかで人にpandasの話をしたらデータフレーム機能が気になるというコメントが多いかな。どれ。さっきの要領でIPython Notebookを起動して。
B: はいはい。カチカチっと。
A: で、import pandasする。
B: へ? いきなり? pandasのインストールは?
A: おっと、話してなかったな。例によってLinuxな人はパッケージを使って入れるべし。Ubuntuならsudo apt-get install pandasとか。Windowsの人は…昔、pandasを試したときにはpip install pandasでさくっと入ったのでそれを勧めるつもりだったんだが、この原稿の為にPCへインストールしてみようとしたらvcvarsall.batが無いと言いやがるんだよな。vcvarsall.batが要るということは、正攻法でインストールするにはPythonのバージョンに対応したVisual C++が必要ということだ。それは面倒くさい。ちょー面倒くさい。
B: Pythonのバージョンに対応したVisual C++…?
A: 要するにWindows版PythonをビルドしたVisual C++(以下VC++)が必要なのだ。今のところPsychoPyなどのパッケージはPython 2.7で動くからこの講座でも2.7を使っているわけだが、2.7はVC++ 2008という古いバージョンのVC++でビルドされている。だからVC++ 2008を入手しないといかんわけだが、今から新たに入手するのはちょっと面倒なのだ。そゆこと。
B: えっ、じゃあどうしたらいいんですか。
A: 例によって非公式インストーラーを利用させていただく。Unofficial Windows Binaries for Python Extension Packages( http://www.lfd.uci.edu/~gohlke/pythonlibs/ )だね。本当にありがたいサイトだ。ここからpandasのインストーラーをダウンロードしてダブルクリックして実行してインストール。おしまい。
B: おお、素晴らしいですな。
注釈
2015/05/30追記:現在ではwheelで簡単にインストールできるようになっています。
A: あと、タイムゾーンを扱うためにpytzというパッケージが必要だ。これは普通にpip install pytzでインストールできる。Numpyなんかも当然必要だし、これからのサンプルではIPython NotebookやMatplotlib、rpy2もインストール済みという前提で進める。
B: IPythonはすでに使ってますがな。
A: (無視して)さて、pandasのインストールが済んだら改めてIPython Notebookを起動しよう。新しいノートを開いてimport pandasする。これでpandasが使える。
B: やっとスタートですね。それではお手並み拝見。
A: お題がないとやりにくいので、実習の授業データを使うことにする。いわゆるtilt illusionの実験で、周囲のcontextの角度によって中心のtest stimulusがどちらに傾いて見えるか判断させてPSEを求めた結果を示している。正の方向がClockwiseである。
B: あ、これ真っ直ぐなのに傾いて見える気持ち悪い奴ですよね。
A: 実験参加者は7人で、C20、CC20、C70、CC70の4条件すべてに参加している。CはClockwise、CCはCounterClockwise。20と70はそれぞれcontextの回転角度。0度で垂直方向のグレーティング。データはpsedata.csvというCSV形式のファイルとしてIPython Notebookの保存ディレクトリに置かれているとする。
B: ふむふむ。
A: で、このpsedata.csvの内容をpandasを使って変数dataframeにざっくり読み込む。
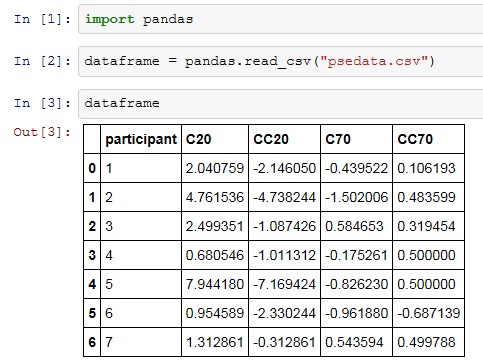
B: おおう。これだけで読めるんですか?
A: 読める。タブ区切りや欠損値などの扱いも細かく指定できる。細かすぎて解説が鬱陶しいので先へ進む。
B: ちょ、アンタ!
A: ファイルを読み込んで生成されたのはpandas.core.frame.DataFrameというクラスのオブジェクトである。いわゆるデータフレームと言う奴だな。このクラスはnumpy.ndarrayのようにmean( )やstd( )のメソッドを持つ。当然、numpy.ndarrayのようにaxisオプションで平均を計算する方向を指定できる。
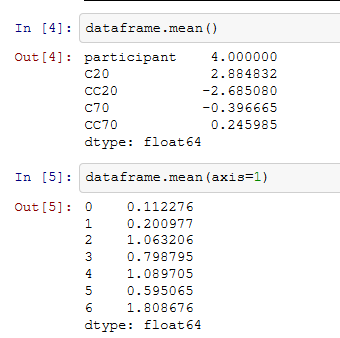
B: おおっ!
A: pandas.core.frame.DataFrameや、こいつにmean( )を適用して得られるpandas.core.series.Seriesクラスのオブジェクトはplot( )をメソッドとして持っているのでこんな風にざっくりと平均値をプロットしたりも出来る。
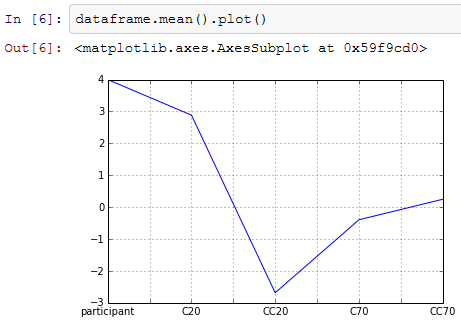
B: おおう!なんだか知らないけど今ぼくは猛烈に感動しています!
A: ま、ざっくりParticipantまで平均してプロットしているのはご愛嬌だがな。
B: あ、ほんとだ。ちょっと冷静になったぞ。これじゃいくらなんでもざっくりしすぎでは?
A: pandas.core.frame.DataFrameに列名を並べたリストを与えると、その列を抜き出したデータフレームが新規作成される。上の折れ線グラフと違ってC20、C70、CC20、CC70の順に抜き出している点にも注目してほしい。
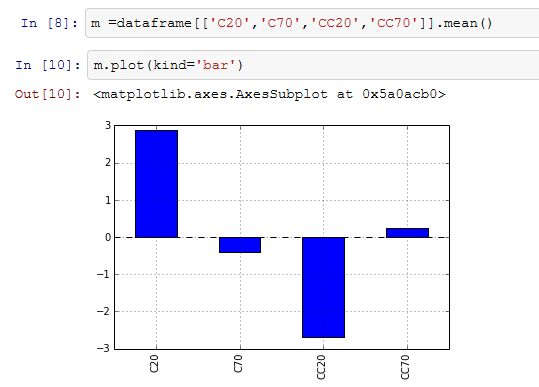
B: のおおおお! しかも棒グラフになってる!なんだこの便利さは! エラーバーは! エラーバーはつかないんですか!!!!
A: ちょっと落ち着け。よく見るとグラフのすぐ上に<matplotlib.axes.AxesSubplot at ...>などと書いてあるように、pandasはmatplotlibを呼んでいるだけである。ということは、matplotlibのテクニックが応用できる。そら。
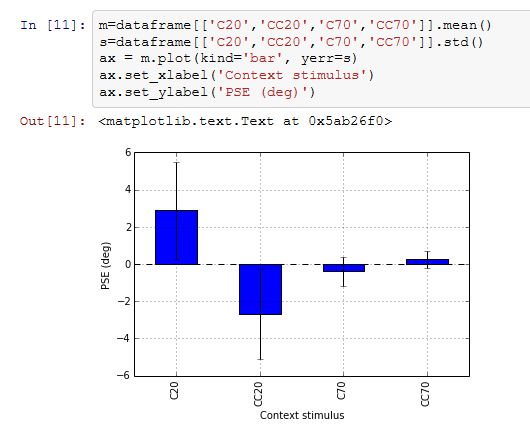
B: うああああ! あのまだ無垢な少年だった頃の僕を悩ませたエラーバーが、たったこれだけで付けられるなんて! ちくしょう!許さねえ!
A: 誰を許さないってんだよ。matplotlibの解説の時にもエラーバーを付けて見せたのにそん時は全然騒がなかったじゃないか。
B: あんなちーまちーまコードを書いた末に出来ても何とも思いませんが、この、やたら、簡単っぽいのが、許せない!
A: なんだか変なスイッチが入っちまったなあ。
B: はあはあ…。(蒼白な顔をして) はっ!もしかして、まさか…
A: ん?どうした?
B: まさか、2色の棒グラフとかまでぱぱっと書けたりしないですよね? しかもそれにきちんとエラーバーまでつけられたりなんかしないですよね?よね?
A: 2色の棒グラフ? 少なくとも今のままでは出来ないなあ。元にしたデータファイルの並びがよくない。ちょっと加工せにゃならん。
B: ちょっと…?ちょっとだけ?
A: うむ。私もpandasはそんなに使い込んでいないのでアレなんだが。インデックスを作る必要がある。pandas.MultiIndex.from_arrays()を使ってそれぞれの列がどの条件に対応しているかのインデックスを作る。

B: …(固唾をのんで見守っている)
A: 引数は被験者番号が0から6まで並んだのが2回繰り返されたリストと、ClockwiseとCounterClockwiseというラベルが7個ずつ並んだリストをまとめた多重リストだ。そしてそれぞれのリストにParticipant、Direction of context stimulusという名前を付けている。contextの回転量が20度の列と70度の列にデータをまとめようという狙いだ。
B: …。
A: インデックスが出来たので、今度はインデックスに合うようにデータを並び替える。ここでちょっとpandasだけでは面倒くさいのでnumpyの力を借りよう。import numpy as npする。そして、元のデータフレームのC20、CC20、C70、CC70の列を抜き出してリストにして、2行14列の行列を作った後にえいやっとtranspose()する。これで14行2列のデータが出来た。このデータと先ほど作成したインデックス、そして列名に20deg、70degという文字列を与えてpandas.DataFrameに与えてデータフレームを作る。
B: (ここでほっとした表情で笑みを浮かべて肩の力が抜ける)
A: 並び替えをしたデータフレームを確認してみよう。こんな感じだ。
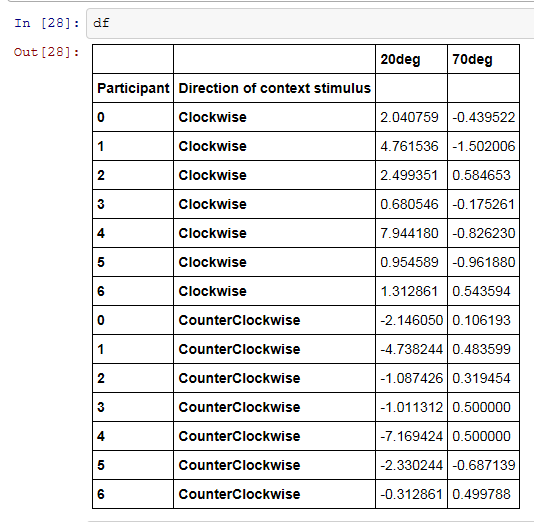
B: (すっかり普段の調子で)ふうん、こうすると何が得なんですか?
A: いろいろあるが、例えばこんな風にインデックスの名前を用いてデータの抽出が出来る。これはDirection of context stimulus別に平均値を求めた例ね。

B: ほほう。これはこれは。
A: インデックスの名前の他にも、インデックスのレベルを用いても抽出が出来る。レベルと言うのはインデックスを作成した時の配列の順番で、今回の場合はParticipantがlevel 0、Direction of context stimulusがlevel 1である。だから、mean( )やstd( )の引数にlevel=1と書いてもDirection of context stimulus別に計算が出来る。

A: そしてさっきB君が言っていたエラーバー付きの2色の棒グラフ。この状態まで準備が出来ていれば、さっきと全く同じようにmean( )の戻り値のplot( )メソッドを呼ぶことで描画することが出来る。横軸にきちんと軸ラベルが付いていることに注目。(注:pandas 0.14.1で動作確認; 0.13.1ではエラーで描画できず)
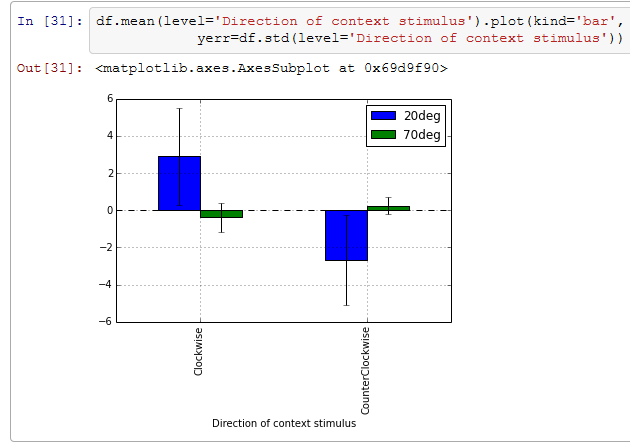
B: ほほう…。なかなか。
A: なんだよ、さっきはあんなに取り乱していたくせに。B君が言っていたのはこのグラフではないのか?
B: このグラフですよ。ふふっ、でもですねAさん、もうnumpyがなんだのtransposeがかんだの言っている時点でもう僕の勝利は揺るがないのです!あの忌まわしい心理学実験のレポートの日々から磨き上げてきたExcelグラフ職人としての僕の誇りは守られたのだ!
A: …やっぱりまだあっちの世界に行ったままだな。
B: ん?何か?
A: いや。まあその誇りを胸に世界に羽ばたいてくれたまへ。この棒グラフだが、横軸だけラベルがついていて縦軸にラベルが無いのも癪なので、ちょっと書き換えてみた。一行が長ったらしくなるので平均値と標準偏差を先に計算して変数mとsに格納してある。
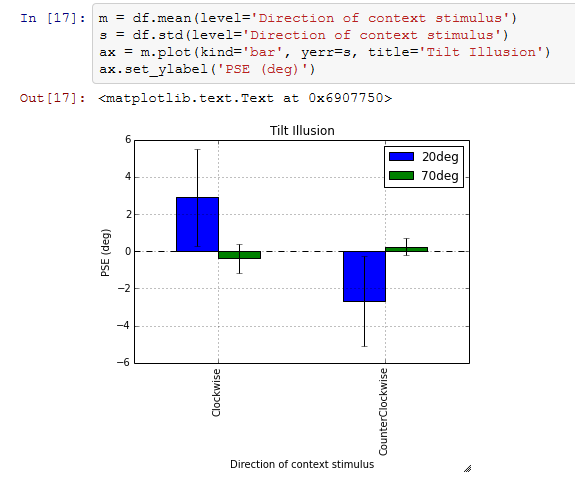
B: むっ、やはり侮れないな。また対抗意識がめらめらと…
A: ちょっと残念なのが、上の方のグラフでも使ってしまってるのだがset_ylabel( )メソッドを使っていること。ざっとグラフを描くところまではいいんだけど、細かいとこを調節しようとしたら結局matplotlibが顔を見せてしまう。ご本尊というやつだね。さらに言うと、データの並び替えにnumpyが出てきたのも残念。numpyを使わずにできなくもないんだけど、ちょっと面倒くさい。どうせmatplotlibやnumpyを直接使わないといけないとなると、じゃあ最初からmatplotlibとnumpyでいいじゃないかという気がしなくもない。ていうか、それが理由で私はいまいちpandasに移行する気がしないんだよね。
B: むむーん。
A: ま、これで終わるつもりだったんだけど今こう言いながらちょっとだけpandasを応援したい気がしてきたので少しだけpandasで遊んでみる。stack()、unstack()というのを使うと結構柔軟にデータの並び替えが出来る。まずstack()を用いると、データフレームの列をつぶしてデータを積み上げることが出来る。
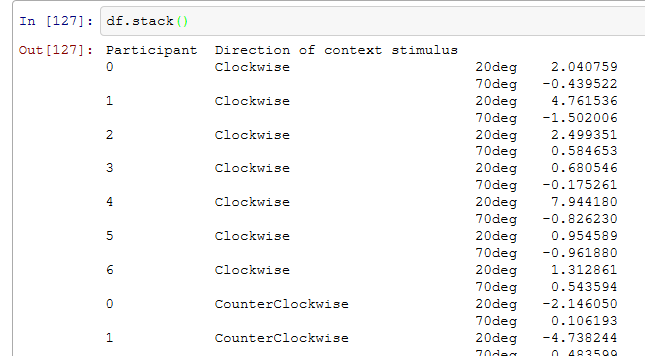
B: あれっ、表の罫線みたいなのが消えちゃいましたが。
A: stack()によってデータフレームからpandas.core.series.Seriesクラスのオブジェクトになったからだと思われる。こいつをpandas.DataFrameでデータフレームに戻す。ついでに20deg/70degのインデックスに名前が無いから新しく作成したデータフレームのindex.namesに名前を並べたリストを代入する。
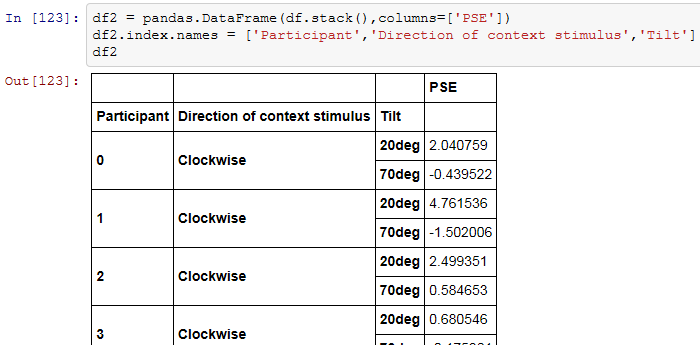
B: ふむふむ。それで?
A: unstack()することで、積み上げた列を崩して並び替えることが出来る。例えばunstack('Participant')とするとこんな風に列方向にParticipantsが並べたデータフレームに変換される。
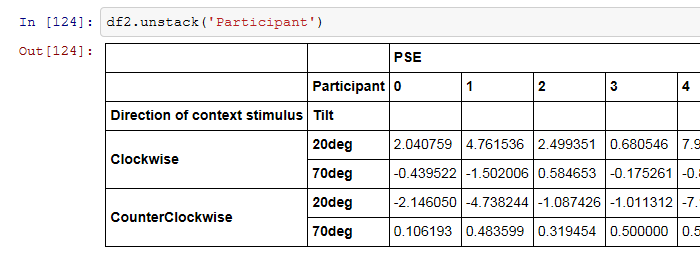
B: !!
A: 当然、unstack('Direction of context stimulus')とするとこうなる。さっきと同様にインデックス名じゃなくてunstack(1)としても同じ結果が得られる。
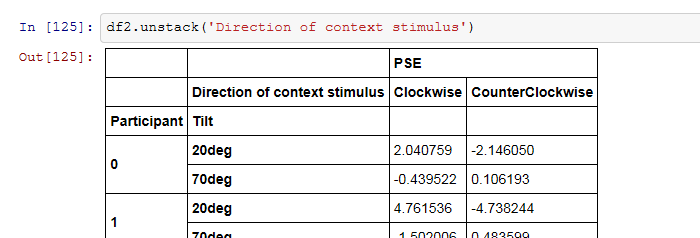
B: な、な、…といういうことは、unstack('Tilt')したら…
A: こうだね。
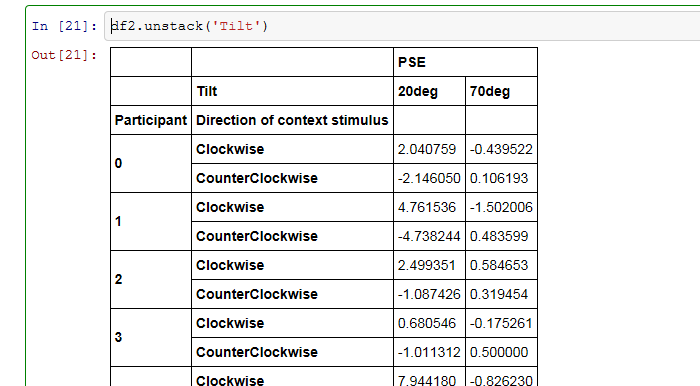
B: ぐふぁっ!
A: さっき棒グラフを書くときに私が作ったデータフレームはTiltでunpack()したものに相当するわけだが、Direction of context stimulusでunpack()してTiltでmeanとstdを計算すれば、さっきの棒グラフの横軸をTiltにした棒グラフも簡単に作れる。
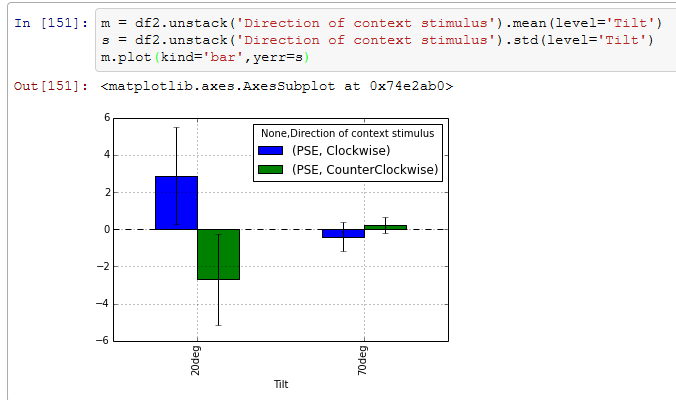
B: うう、ま、負けたかもしれない…この僕が…(ガクッ)
A: さっきからキミは何と戦っとるんだ。
B: Aさんにはわからんとですよ。この僕の気持ちは。
A: 他にもいろいろな並び替えや抽出が出来るので、興味を持った人はpandasの公式ドキュメントのこの辺り( http://pandas.pydata.org/pandas-docs/stable/reshaping.html )とかをじっくり見て欲しい。最後にちょっとpandasの残念な話。pandasにはpandas.rpy.commonというモジュールがあって、こいつにconvert_to_r_matrixという関数がある。これを使うとpandasのデータフレームをごっそりrpy2で使うデータフレームに変換できる。
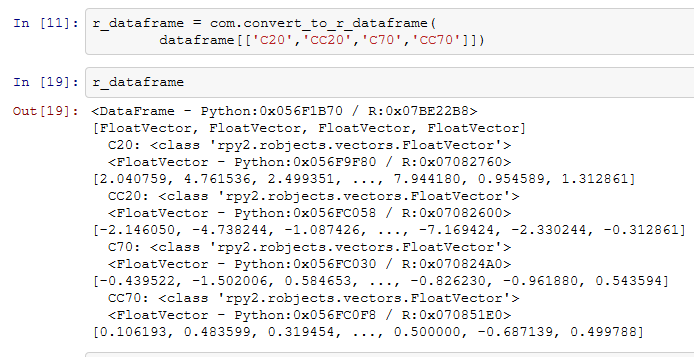
B: …(まだいじけている)
A: そうするとpandasでざっとデータを確認したりグラフを描いた後、rpy2を使って統計処理をしたいと考えるのは自然な流れ。ところが公式ドキュメントのこの辺り( http://pandas.pydata.org/pandas-docs/dev/r_interface.html が書きかけ状態で、いまいち使い方がよくわからない。まあともかくrpy2のデータフレームに変換出来りゃ後は例題22-1の方法でばしっとANOVA君!と思ったらこんな残念な結果に。
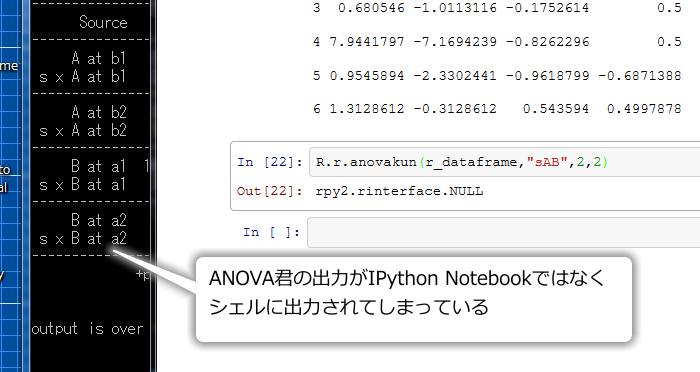
B: (顔を上げて)ん?これはどうなっているんですか?
A: ANOVA君の結果がIPython Notebookではなくてサーバーが走っているシェル上に出てしまっているんだよ。これではお話にならない。
B: そうか、pandasも完全無欠じゃないんですね!ぼくにもまだ存在価値があるのですね!
A: …だからなんでそういう話になるのかと。ま、この辺は今後の発展に期待したいところだね。この記事のために久々にpandasを触ったが、以前に触った時よりはずいぶん好印象を持った。ちょっとした(ピー)な仕事の合間にIPython Notebook上であれこれ作業して、作業を途中で保存してまた再開して、という作業にこの組み合わせは強力だね。まぁまだ全面的に使う気にはならんが、本当にこれからが楽しみなパッケージだ。
B: いつでも迎え撃てるようにExcel芸を磨いておかなければ。ごしごし。
A: (いったいいつまで引っ張るつもりなのか…)
B: なにか?
A: いや、別に。これでSの没原稿の供養は一区切りかな。
B: 他にもいろいろ載っていませんでしたっけ。numpyとかscipyとかmatplotlibとか、ctypesとか。
A: ctypesは例題 9-1 、 9-2 、 21-1 、 21-3 で取り上げている。numpyとmatplotlibは例題 12-2 、 14-1 から 14-5 あたりなど。
B: scipyは?
A: えーと…ホラ、その…(といいながらgrep)、例題14-3とか、20-1とかじゃダメ?
B: scipyの機能の膨大さを考えるといくらなんでも不十分すぎるかと。
A: くっ、scipyなんて例題1回分をまるごと使わないと紹介できないじゃないか、いくらなんでもそこまで時間かけられるかっての。こうみえても今週は(---自主規制---)でめちゃ忙しいんだぞ!
B: それを言ったらpandasも例題1回分まるごとくらい必要だとおもうんですがねー。ま、今日はこの辺にしておいてあげましょう。んじゃS先生のお土産のバウムクーヘンを…、と思ったらない!なくなっている! Aさん!食べましたね!! (めらめら)
A: (冷ややかな目で)その1、最後の一切れを食べたのはB君である。その2、そもそもお土産をもらったのはB君ではなく私である。
B: あ、あれ。そうでしたっけ。いや、よしんば1が正しかったとしても、S先生はAさんにじゃなくてみんなにお土産を持ってきてくれたに違いない!
A: まあそういうことにしておいてやろう。というわけで例題22はこれでおしまい。視覚-聴覚刺激の同期についてあちこちから質問を受けまくっているのでそろそろ扱わんといかんと思っているんだけど、下調べが大変な話題だから次は難しいだろうなあ。